6 Workflow management
- Define what a workflow management system is.
- List the benefits of using a workflow management system.
- Explain the benefits of using Nextflow as part of your bioinformatics workflow.
6.1 Workflows
Analysing data involves a sequence of tasks, including gathering, cleaning, and processing data. These sequence of tasks are called a workflow or a pipeline. These workflows typically require executing multiple software packages, sometimes running on different computing environments, such as a desktop or a compute cluster. Traditionally these workflows have been joined together in scripts using general purpose programming languages such as Bash or Python.
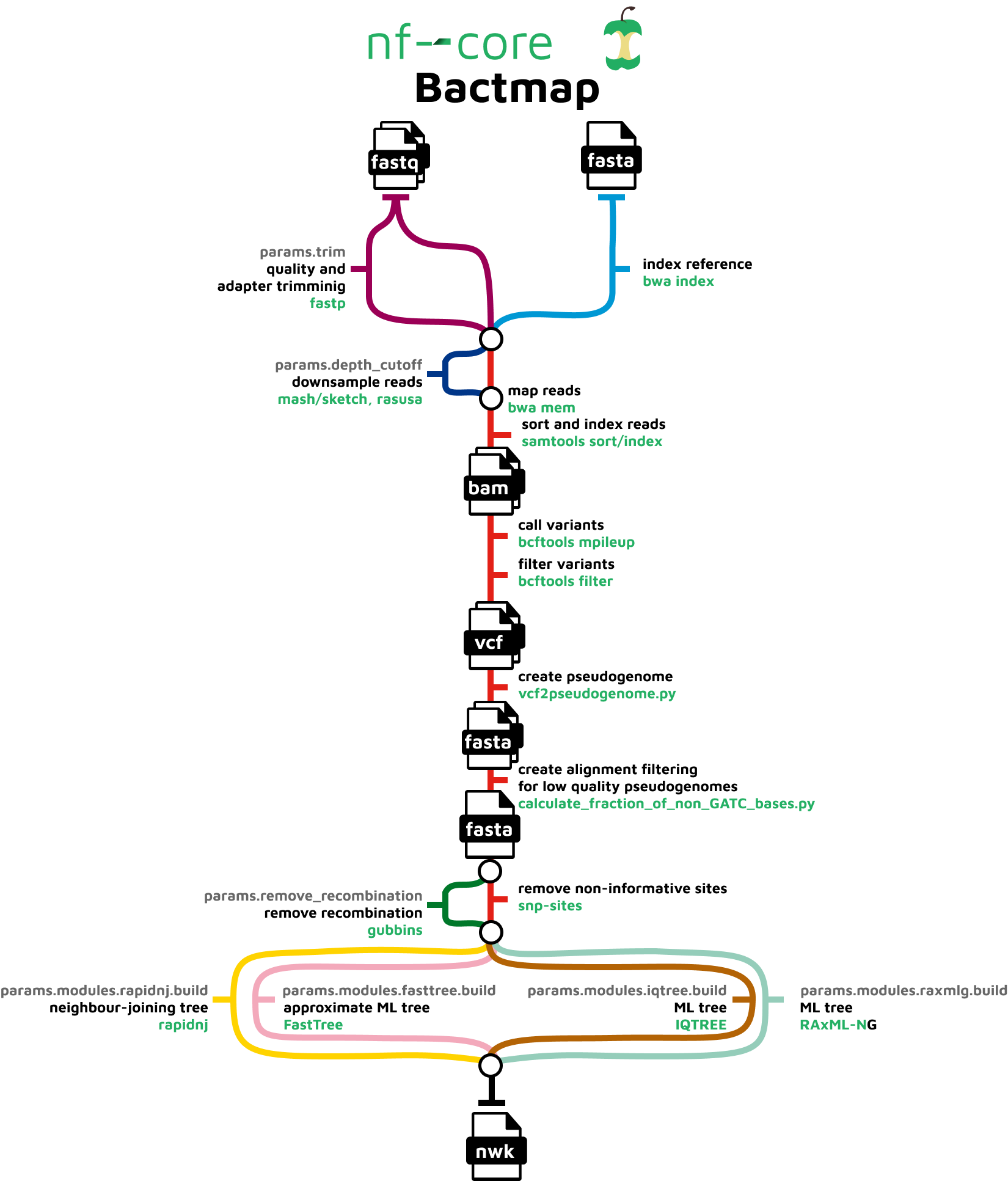
However, as workflows become larger and more complex, the management of the programming logic and software becomes difficult.
6.2 Workflow management systems
Workflow Management Systems (WfMS), such as Snakemake, Galaxy, and Nextflow have been developed specifically to manage computational data-analysis workflows in fields such as Bioinformatics, Imaging, Physics, and Chemistry.
WfMS contain multiple features that simplify the development, monitoring, execution and sharing of pipelines.
Key features include;
- Run time management: Management of program execution on the operating system and splitting tasks and data to run at the same time in a process called parallelisation.
- Software management: Use of technology like containers, such as Docker or Singularity, that packages up code and all its dependencies so the application runs reliably from one computing environment to another.
- Portability & Interoperability: Workflows written on one system can be run on another computing infrastructure e.g., local computer, compute cluster, or cloud infrastructure.
- Reproducibility: The use of software management systems and a pipeline specification means that the workflow will produce the same results when re-run, including on different computing platforms.
- Reentrancy: Continuous checkpoints allow workflows to resume from the last successfully executed steps.
6.3 Nextflow basic concepts
Nextflow is a workflow management system that combines a runtime environment, software that is designed to run other software, and a programming domain specific language (DSL) that eases the writing of computational pipelines.
Nextflow is built around the idea that Linux is the lingua franca of data science. Nextflow follows Linux’s “small pieces loosely joined” philosophy: in which many simple but powerful command-line and scripting tools, when chained together, facilitate more complex data manipulations.
Nextflow extends this approach, adding the ability to define complex program interactions and an accessible (high-level) parallel computational environment based on the dataflow programming model, whereby processes are connected via their outputs and inputs to other processes, and run as soon as they receive an input. The diagram below illustrates the differences between a dataflow model and a simple linear program .
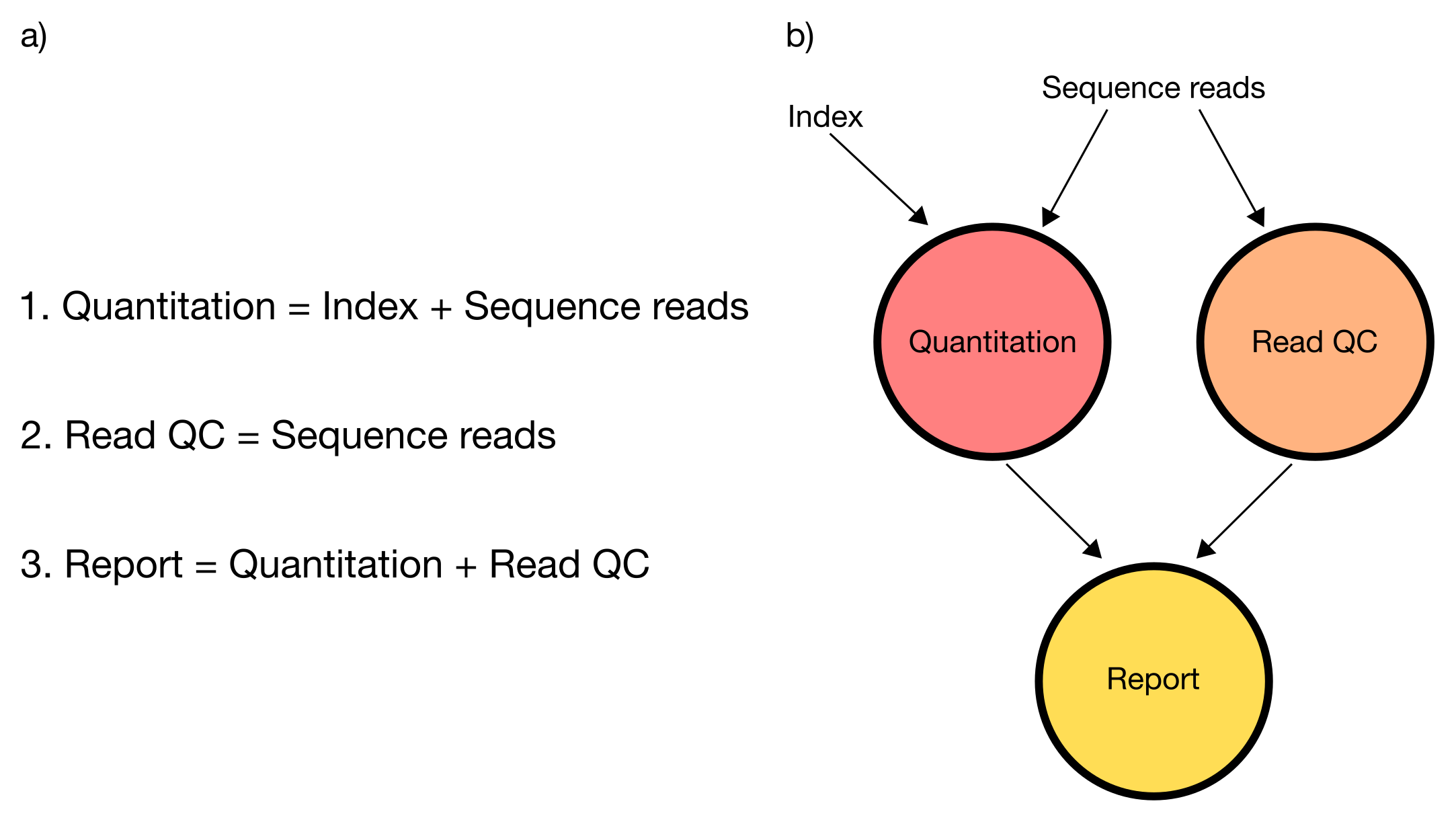
In a simple program (a), these statements would be executed sequentially. Thus, the program would execute in three units of time. In the dataflow programming model (b), this program takes only two units of time. This is because the read quantitation and QC steps have no dependencies on each other and therefore can execute simultaneously in parallel.
6.3.1 Nextflow core features
Fast prototyping: A simple syntax for writing pipelines that enables you to reuse existing scripts and tools for fast prototyping.
Reproducibility: Nextflow supports several container technologies, such as Docker and Singularity, as well as the package manager Conda. This, along with the integration of the GitHub code sharing platform, allows you to write self-contained pipelines, manage versions and to reproduce any former configuration.
Portability: Nextflow’s syntax separates the functional logic (the steps of the workflow) from the execution settings (how the workflow is executed). This allows the pipeline to be run on multiple platforms, e.g. local compute vs. a university compute cluster or a cloud service like AWS, without changing the steps of the workflow.
Simple parallelism: Nextflow is based on the dataflow programming model which greatly simplifies the splitting of tasks that can be run at the same time (parallelisation).
Continuous checkpoints: All the intermediate results produced during the pipeline execution are automatically tracked. This allows you to resume its execution from the last successfully executed step, no matter what the reason was for it stopping.
6.3.2 Scripting language
Nextflow scripts are written using a language intended to simplify the writing of workflows. Languages written for a specific field are called Domain Specific Languages (DSL), e.g., SQL is used to work with databases, and AWK is designed for text processing.
In practical terms the Nextflow scripting language is an extension of the Groovy programming language, which in turn is a super-set of the Java programming language. Groovy simplifies the writing of code and is more approachable than Java. Groovy semantics (syntax, control structures, etc) are documented here.
The approach of having a simple DSL built on top of a more powerful general purpose programming language makes Nextflow very flexible. The Nextflow syntax can handle most workflow use cases with ease, and then Groovy can be used to handle corner cases which may be difficult to implement using the DSL.
6.3.3 DSL2 syntax
Nextflow (version > 20.07.1) provides a revised syntax to the original DSL, known as DSL2. The DSL2 syntax introduces several improvements such as modularity (separating components to provide flexibility and enable reuse), and improved data flow manipulation. This further simplifies the writing of complex data analysis pipelines, and enhances workflow readability, and reusability.
6.3.4 Processes, channels, and workflows
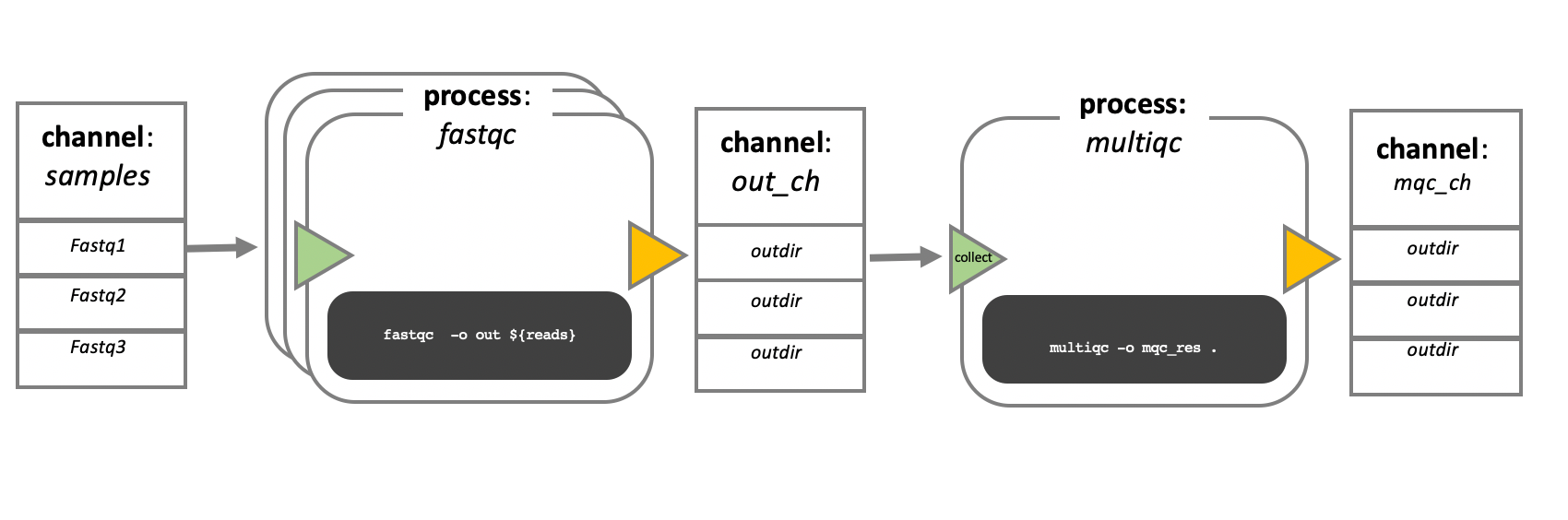
Nextflow workflows have three main parts; processes, channels, and workflows. Processes describe a task to be run. A process script can be written in any scripting language that can be executed by the Linux platform (Bash, Perl, Ruby, Python, etc.). Processes spawn a task for each complete input set. Each task is executed independently, and cannot interact with another task. The only way data can be passed between process tasks is via asynchronous queues, called channels.
Processes define inputs and outputs for a task. Channels are then used to manipulate the flow of data from one process to the next. The interaction between processes, and ultimately the pipeline execution flow itself, is then explicitly defined in a workflow section.
In the following example we have a channel containing three elements, e.g., 3 data files. We have a process that takes the channel as input. Since the channel has three elements, three independent instances (tasks) of that process are run in parallel. Each task generates an output, which is passed to another channel and used as input for the next process.
6.3.5 Workflow execution
While a process defines what command or script has to be executed, the executor determines how that script is actually run in the target system.
If not otherwise specified, processes are executed on the local computer. The local executor is very useful for pipeline development, testing, and small scale workflows, but for large scale computational pipelines, a High Performance Cluster (HPC) or Cloud platform is often required.
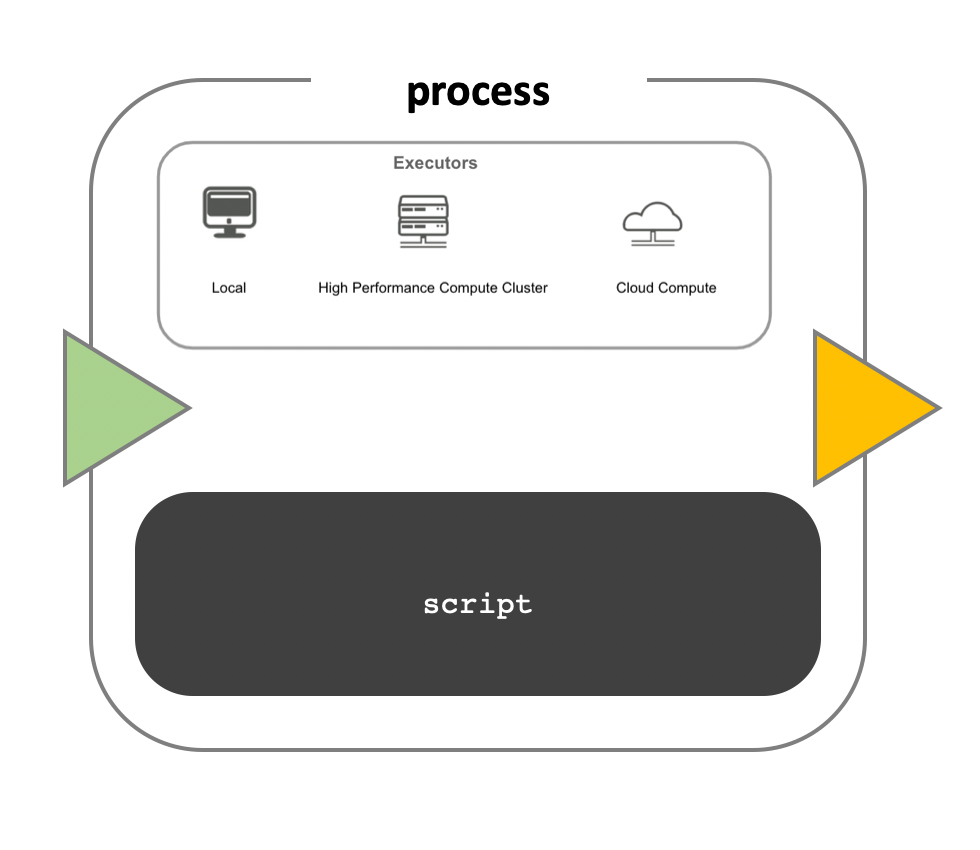
Nextflow provides a separation between the pipeline’s functional logic and the underlying execution platform. This makes it possible to write a pipeline once, and then run it on your computer, compute cluster, or the cloud, without modifying the workflow, by defining the target execution platform in a configuration file.
Nextflow provides out-of-the-box support for major batch schedulers and cloud platforms such as Sun Grid Engine, SLURM job scheduler, AWS Batch service and Kubernetes. A full list can be found here.
6.4 Snakemake
In this section we’ve focused on Nextflow but many people in the bioinformatics community use Snakemake. Similar to Nextflow, the Snakemake workflow management system is a tool for creating reproducible and scalable data analyses and it supports all the same features mentioned above. Perhaps the most noticeable difference for users is that Snakemake is based on the Python programming language. This makes it more approachable for those already familiar with this language.
6.5 Summary
- Workflow management software is designed to simplify the process of orchestrating complex computational pipelines that involve various tasks, inputs and outputs, and parallel processing.
- Using workfow managent software to manage complex pipelines has several advantages: reproducibility, parallel task execution, automatic software management, scalability (from a local computer to cloud and HPC cluster servers) and “checkpoint and resume” ability.
- Nextflow and Snakemake are two of the most popular workflow managers used in bioinformatics, with an active community of developers and several useful features:
- Flexible syntax that can be adapted to any task.
- The ability to reuse and share modules written by the community.
- Integration with code sharing platforms such as GitHub and GitLab.
- Use of containerisation solutions (Docker and Singularity) and software package managers such as Conda.
6.6 Credit
Information on this page has been adapted and modified from the following source(s):
- Graeme R. Grimes, Evan Floden, Paolo Di Tommaso, Phil Ewels and Maxime Garcia. Introduction to Workflows with Nextflow and nf-core. https://github.com/carpentries-incubator/workflows-nextflow 2021.