5 Comparing protein structures
- Align protein structures using structural alignment tools such as MatchMaker.
- Compare predicted models with experimentally solved structures.
- Interpret structural differences using RMSD-based colouring.
- Recognise when global alignments fail for multidomain proteins.
- Evaluate the consistency of multiple AlphaFold predictions.
- Identify conserved structural features across species.
5.1 Overview
Predicting a protein structure is only the first step. We must also ask an important question:
How reliable is this model?
One useful approach is structural comparison. By aligning a predicted structure with other models or experimentally solved structures, we can:
- evaluate whether the predicted fold is plausible
- identify conserved structural regions
- detect flexible or uncertain parts of the protein
In this section we will explore several common comparison scenarios:
- compare a predicted structure with homologous experimental structures
- compare predictions from different AlphaFold versions
- compare multiple predictions of the same protein
- interpret structural differences using RMSD colouring
5.2 Example protein: SLC52A2
We will begin with a human protein called SLC52A2 (UniProt ID: Q9HAB3).
SLC52A2 is a membrane transporter for vitamin B2 (riboflavin). Mutations in this protein can cause a childhood-onset neurological disorder called Brown-Vialetto-Van Laere syndrome.
Many of these mutations reduce protein expression, or riboflavin transport activity. At present, no experimentally determined structure exists for the human protein. This makes it a good example for exploring how predicted structures can be evaluated using structural comparisons.
First, we load the AlphaFold prediction from AlphaFoldDB:
close
alphafold fetch Q9HAB3 version 6
hide atoms
color #1 salmon5.3 Searching for homologous structures
Even when a protein has no solved structure, related proteins may have been crystallised. If a homologous structure exists, we can align it to our model and examine how well the folds match.
Two web-based tools for comparing protein structures are:
- DALI - high-sensitivity method of structure alignment (Holm et al. 2023)
- FoldSeek - rapid structure search at proteome scale (van Kempen et al. 2024)
Both of these tools allow searching structural databases using the three-dimensional fold rather than sequence similarity alone.
5.3.1 FoldSeek
FoldSeek can be accessed:
- Through the FoldSeek web server
- Directly within ChimeraX:
Tools > Structure Comparison > FoldSeek
After submiting a PDB file, FoldSeek will return a ranked list of similar structures against several of its databases. For experimentally-resolved structures, the most relevant database is the PDB100.
The results table includes:
- Target: The PDB ID of each hit, with a suffix indicating the assembly and specific chain. E.g.
6ob6-assembly1_Arefers to chain A of the first assembly in PDB entry 6OB6. - Description: A short description of the hit, often including the protein name.
- Scientific name: The species from which the structure was derived.
- Prob: The probability that the hit is a true structural homologue.
- Seq. Id.: The identity between the aligned sequences of the hit and the query.
- E-Value: The expectation value for the hit, indicating the significance of the match. Lower E-values indicate more significant matches.
- Position in query: A schematic representation of the range of residues in the query structure that align with the hit.
- Alignment: Clicking this button will display the sequence alignment between the query and the hit, along with a superposition of the two structures.
The top hits often include structures with similar folds, even if their sequences are very different. For example, one of the top hits for SLC52A2 the Human equilibrative nucleoside transporter-1 (PDB 6OB6), which shares only ~12% sequence identity with SLC52A2.
The structural alignment provides two scores:
- TM-score: A measure of structural similarity that is independent of protein length. Scores above 0.5 generally indicate similar folds.
- RMSD: The root mean square deviation of atomic positions after superposition. Lower RMSD values indicate better structural agreement.
You may often see references to “PDB25”, “PDB50”, “PDB90” or “PDB100” in the results of database searching tools such as FoldSeek and DALI.
These refer to different versions of the Protein Data Bank (PDB) that have been filtered to remove redundant structures based on sequence similarity.
- PDB25 - contains only one representative structure for each cluster of sequences with >25% identity. This is a highly non-redundant set, useful for identifying distant homologues.
- PDB50 - contains one representative for each cluster of sequences with >50% identity. This is a moderately non-redundant set, useful for general searches.
- PDB90 - contains one representative for each cluster of sequences with >90% identity. This is a less redundant set, useful for finding closely related structures.
- PDB100 - contains all structures in the PDB, only removing chains that are 100% identical. This is the most comprehensive set, but may include many similar structures.
5.3.2 DALI
DALI can be accessed from the DALI web server. Click on “PDB Search” and upload your structure file to search for similar folds in the PDB.
The results will often be similar to FoldSeek, although the ranking of hits may differ due to differences in the underlying algorithms.
One the job completes, you can choose to view the results from against different redundancy-filtered versions of the PDB (see information box above). DALI provides three target lists: PDB25, PDB50 and PDB90. Lower numbers remove more redundancy and highlight more distant structural relationships. You can also view the results against the full PDB, which may include more redundant structures.
The results table includes:
- Chain: The PDB ID and chain of the hit structure. E.g.
6OB6-Arefers to chain A of PDB entry 6OB6. - Z: A Z-score indicating the significance of the structural match. Higher Z-scores indicate more significant matches, with scores above 2 generally considered significant.
- rmsd: The root mean square deviation of atomic positions after superposition. Lower RMSD values indicate better structural agreement.
- lali: The number of aligned residues between the query and the hit.
- nres: The total number of residues in the hit structure.
- %id: The percentage of identical residues in the aligned region between the query and the hit.
- PDB: A link to the PDB structure.
- Description: A brief description of the hit structure.
You can select a hit and click:
- Structural Alignment to view the sequence alignment
- 3D Superposition to view the 3D alignment of the two structures
The DALI server currently only supports HTTP (rather than HTTPS), which may cause security warnings in modern browsers. Although unlikely, data transferred over HTTP could potentially be intercepted by third parties. If you encounter security warnings, you can usually proceed, however, be cautious if you are working with sensitive data.
We have also sometimes found the DALI server to be unstable, with long wait times or failed jobs. You may experience a “Connection has timed out” error after submitting a job. We have found that refreshing the results page after a while will often reveal the results.
5.4 Structural alignment with MatchMaker
Once we have identified a homologous structure, we can perform a structural alignment in ChimeraX to compare the folds in more detail.
As an example, consider one of the top FoldSeek hits for SLC52A2: 6OB6. We can import this structure into the session:
open 6ob6
label delete
hide atomsBefore aligning structures, it is helpful to check the models and chains present in the session:
info chainschain id #1/A chain_id A
chain id #2/A chain_id A
chain id #2/B chain_id BHere we see that:
- the AlphaFold model is stored in model #1
- the PDB structure is stored in model #2
- the experimental structure contains two chains (A and B)
We are now ready to perform a structural alignment.
ChimeraX provides the MatchMaker (mm) command for structural alignment.
mm #1 to #2 showAlignment trueThis command:
- aligns model #1 (the predicted structure) to model #2 (the experimental structure)
- displays the sequence alignment in the Sequence Viewer
Structural alignment works by finding the best superposition of corresponding residues between two structures.
Because the alignment only involves chain B, we hide the other chain to simplify the view:
cartoon hide #2/AThis allows us to focus on the comparison between the predicted model and the experimental structure.
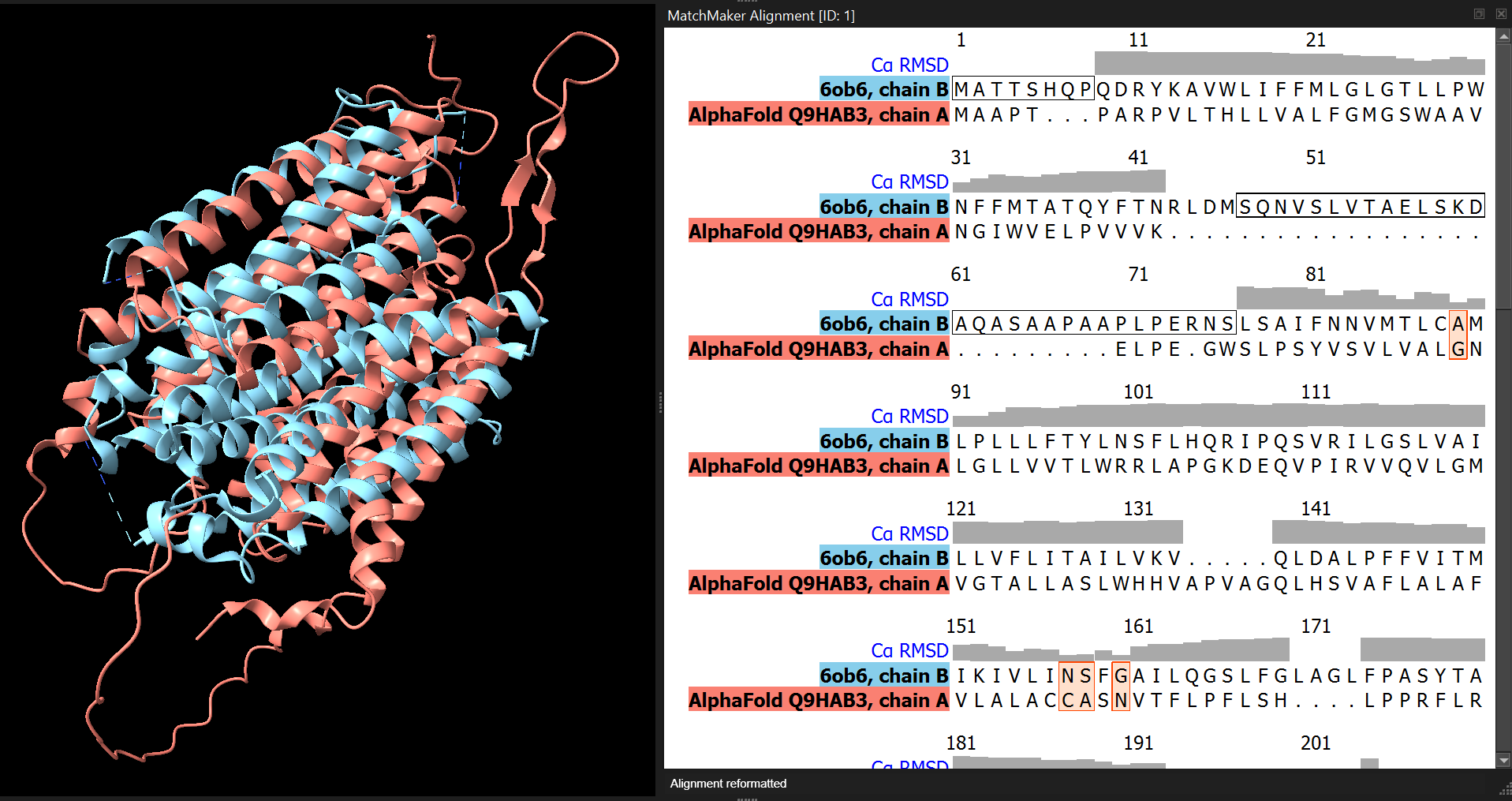
5.5 Visualising structural differences
After the alignment, ChimeraX calculates several useful attributes, including per-residue RMSD values. The attribute seq_rmsd stores the RMSD for each aligned residue.
RMSD measures how far corresponding atoms are apart after structural superposition. Small RMSD values indicate strong agreement between structures.
We can colour the predicted model according to this attribute (we hide the experimental structure to make the colouring easier to see):
color #1 white
color byattribute r:seq_rmsd #1 target csab palette RdYlBu key true
cartoon hide #2This produces a colour gradient showing structural agreement:
- Red - smaller deviation, strong structural agreement
- Yellow - intermediate values
- Blue - larger structural differences
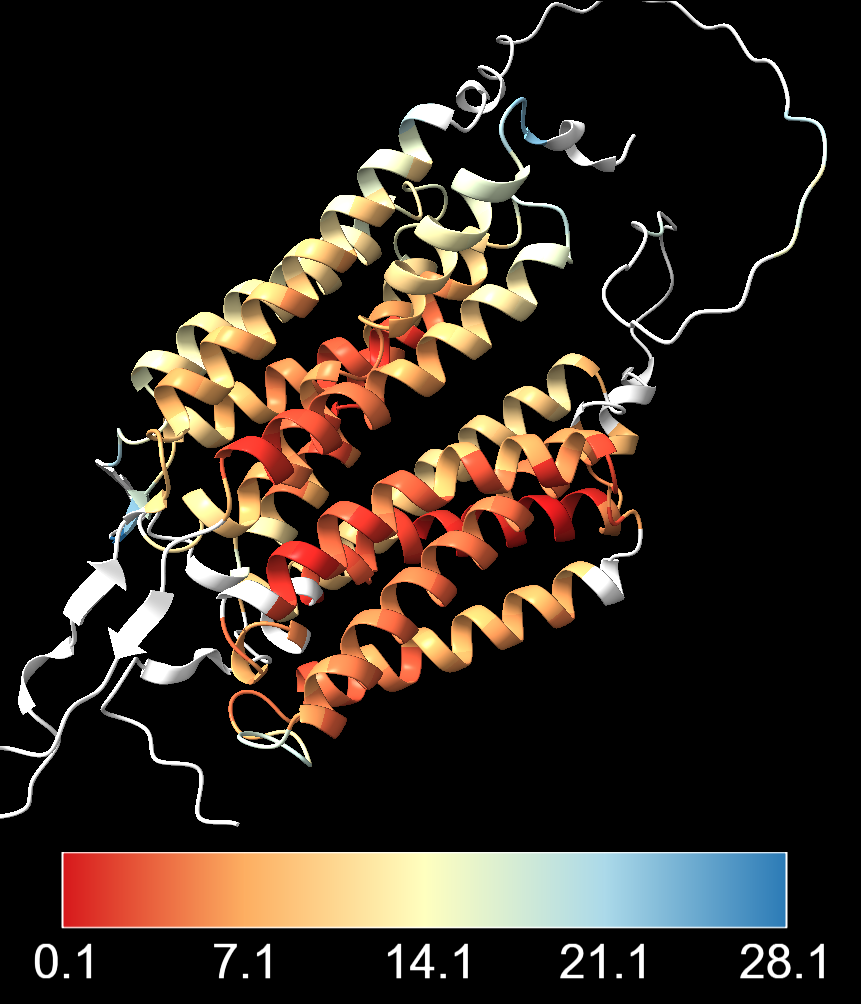
One important thing to note is the choice of colour scale breaks. Above, the breaks between colours are automatically set by ChimeraX based on the distribution of RMSD values. This can sometimes lead to a colour scheme that is dominated by a few outliers with very high RMSD values, making it difficult to see the variation in the rest of the structure. It may also give the impression that most of the structure has very high agreement, when in fact several of the residues have intermediate or even high RMSD values.
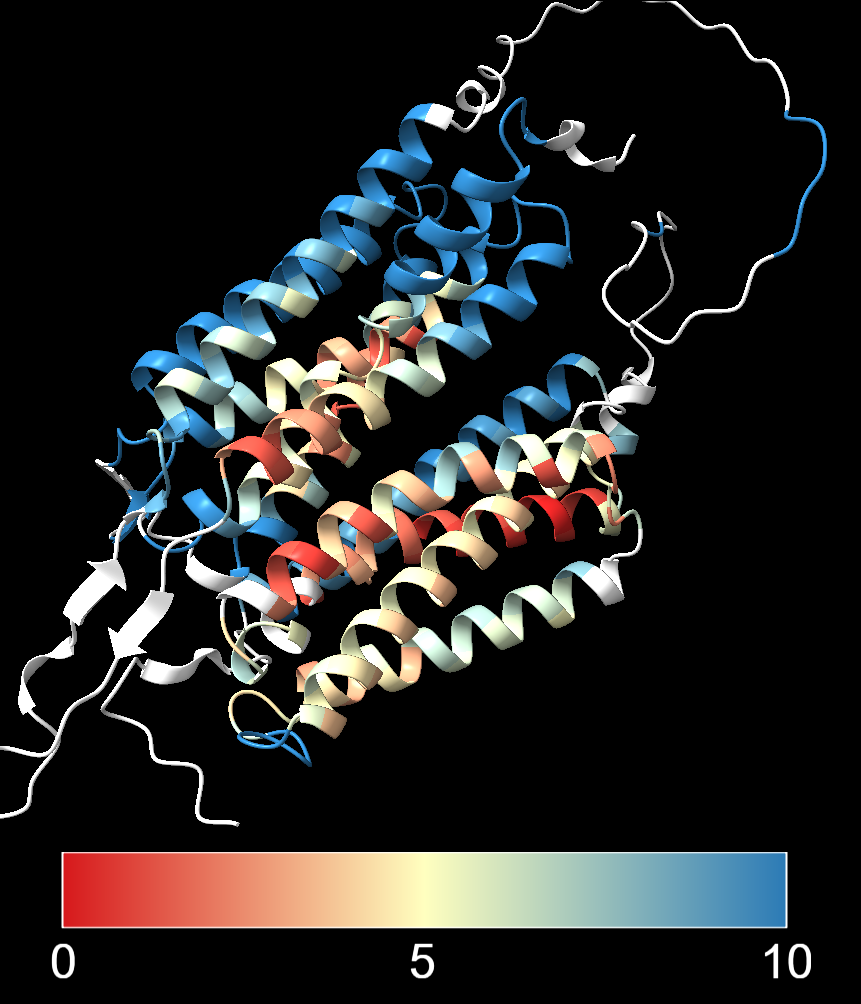
An alternative approach is to set the colour breaks manually, using the graphical user interface “Tools → Structure Analysis → Render/Select by Attribute”:
- Choose: “Attributes of residues”
- Choose: “Attribute: seq_rmsd”
- Adjust colouring thresholds using the sliding bars on the histogram of RMSD values
The image below shows the same alignment with:
- Lower threshold (red) set to 0 Å, indicating perfect agreement
- Midpoint (yellow) set to 5 Å, which would indicate some deviation from the reference structure
- Upper threshold (blue) set to 10 Å, meaning that anything above that value will be coloured blue
5.6 Exercises
Reminder: In this exercise series you are investigating the structure of the amphioxus estrogen receptor and comparing it with experimentally determined human ER structures.
Finally, we will compare our de novo prediction of the LBD region using AlphaFold3 with an experimentally determined human structure that includes the estradiol ligand (PDB: 1ERE).
The PDB entry contains three assemblies of the receptor as a homodimer (i.e. a total of six chains). For simplicity, we will keep only one chain for the comparison:
close
open 1ERE
delete /B-F
hide atoms
show cartoonNext, open the AlphaFold3 prediction of the amphioxus ligand-binding domain:
cd ~/Course_Materials/er_amphioxus/lbd_monomer_af3/
open fold_er_amphioxus_lbd_monomer_af3_model_0.cifQuestions:
- Align the two structures using the PDB structure as the reference. Colour the amphioxus prediction by RMSD.
- Display the ligand atoms in stick style, colour them
gold, and add a ligand surface with 50% transparency. - What can you conclude about the alignment of the amphioxus prediction, particularly around the ligand-binding region?
- Hint: hiding the reference PDB model may help you see the coloured RMSD values.
We align the structures using the MatchMaker command and colour the prediction by RMSD relative to the experimental structure:
mm #2 to #1 showalignment true color byattribute r:seq_rmsd #2 target csab palette RdYlBu key trueThis colours residues in the predicted structure according to their structural deviation from the reference.
We display the ligand in stick representation:
show ligand style ligand stick color ligand gold surface ligand color gold transparency 50After hiding the cartoon representation of the reference structure (
hide #1 cartoon), we can more easily see the RMSD colouring on the amphioxus prediction.We can see that residues forming the ligand-binding pocket show low RMSD values, indicating strong structural agreement with the experimentally determined human structure. This suggests that the architecture of the ligand-binding pocket is highly conserved, even between distantly related species such as amphioxus and humans.
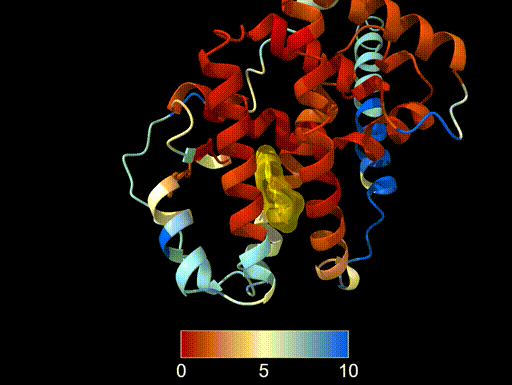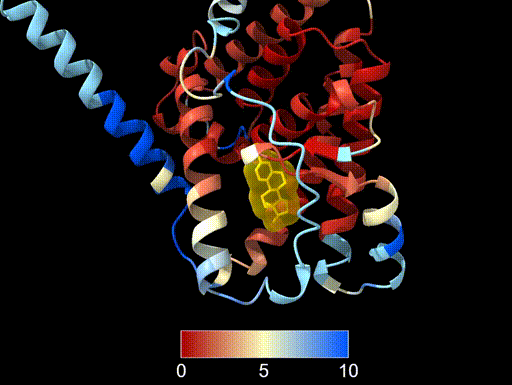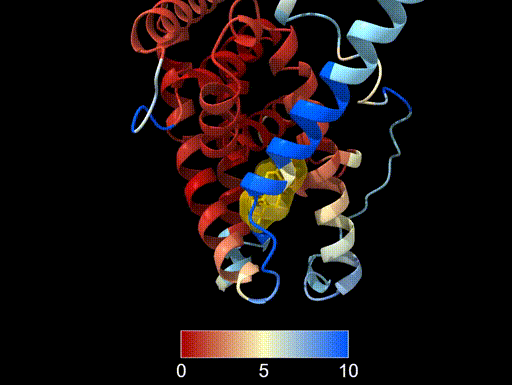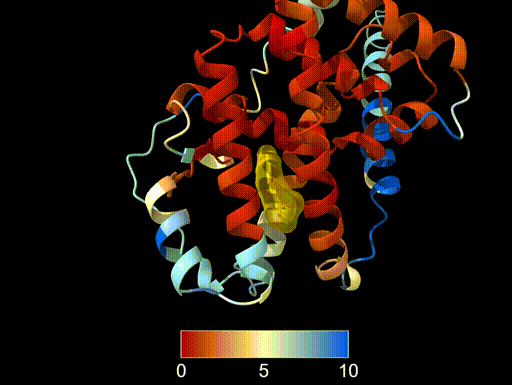
This analysis illustrates how key functional regions of proteins can remain structurally conserved over long evolutionary timescales.
5.7 Summary
Structural comparison tools (e.g. FoldSeek, DALI, or structural alignment methods) can identify related proteins even when sequence similarity is low.
Conserved protein domains often maintain similar three-dimensional folds across large evolutionary distances.
Structural alignment allows comparison of predicted models with experimentally determined structures.
RMSD-based colouring can highlight regions of strong agreement or divergence between structures.