# A collection of R packages designed for data science
library(tidyverse)
# Converts stats functions to a tidyverse-friendly format
library(rstatix)
# Creates diagnostic plots using ggplot2
library(ggResidpanel)14 Two-way ANOVA
Learning outcomes
Questions
- When is the use of a two-way ANOVA appropriate?
- How do I perform this in R?
Objectives
- Be able to perform a two-way ANOVA in R
- Understand the concept of interaction between two predictor variables
- Be able to plot interactions in R
14.1 Libraries and functions
Click to expand
14.1.1 Libraries
14.1.2 Functions
# Creates diagnostic plots
ggResidpanel::resid_panel()
# Creates a linear model
stats::lm()
# Creates an ANOVA table for a linear model
stats::anova()14.1.3 Libraries
# A Python data analysis and manipulation tool
import pandas as pd
# Python equivalent of `ggplot2`
from plotnine import *
# Statistical models, conducting tests and statistical data exploration
import statsmodels.api as sm
# Convenience interface for specifying models using formula strings and DataFrames
import statsmodels.formula.api as smf14.1.4 Functions
# Summary statistics
pandas.DataFrame.describe()
# Plots the first few rows of a DataFrame
pandas.DataFrame.head()
# Reads in a .csv file
pandas.read_csv()
# Creates a model from a formula and data frame
statsmodels.formula.api.ols()
# Creates an ANOVA table for one or more fitted linear models
statsmodels.stats.anova.anova_lm()14.2 Purpose and aim
A two-way analysis of variance is used when we have two categorical predictor variables (or factors) and a single continuous response variable. For example, when we are looking at how body weight (continuous response variable in kilograms) is affected by sex (categorical variable, male or female) and exercise type (categorical variable, control or runner).
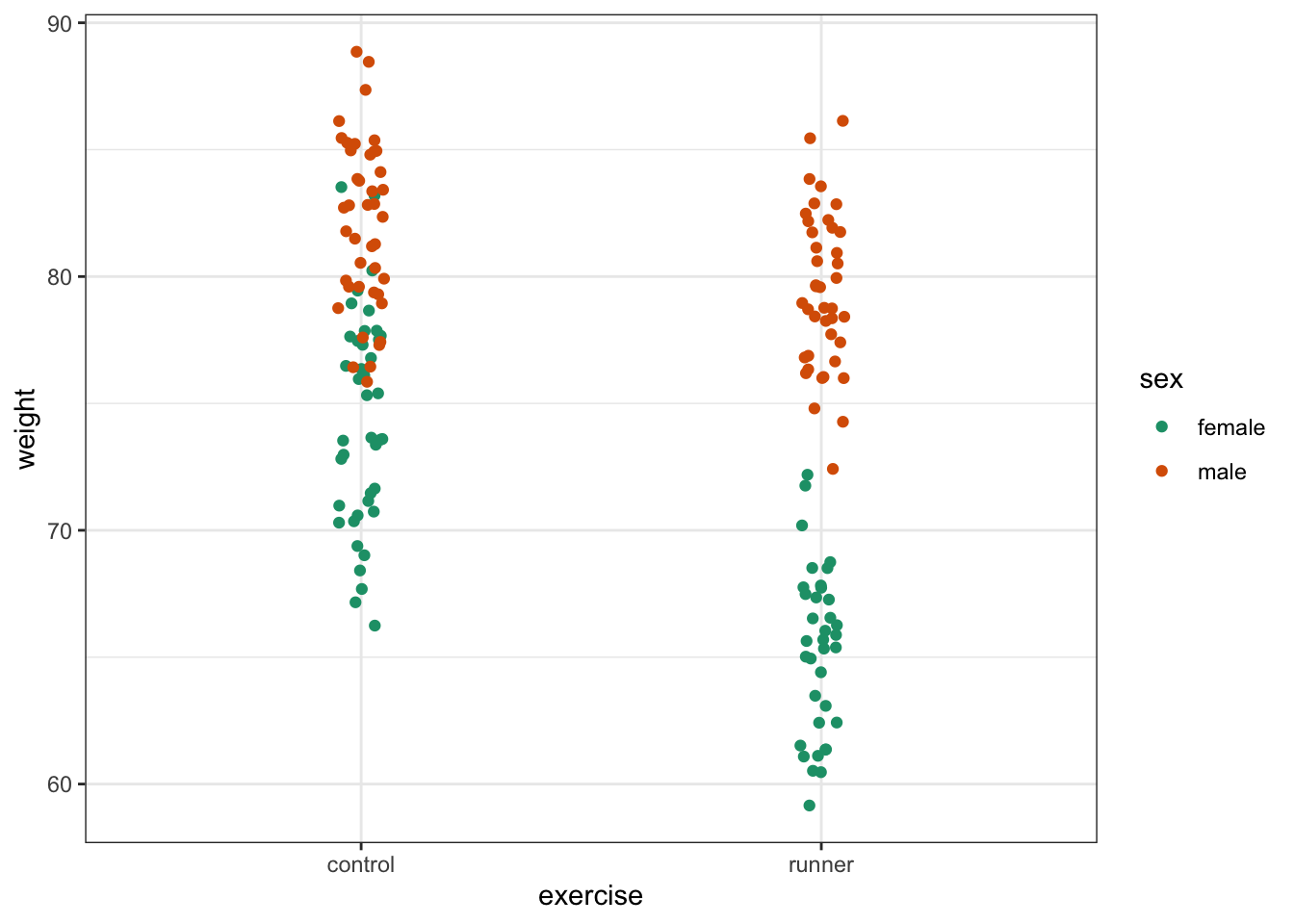
When analysing these type of data there are two things we want to know:
- Does either of the predictor variables have an effect on the response variable i.e. does sex affect body weight? Or does being a runner affect body weight?
- Is there any interaction between the two predictor variables? An interaction would mean that the effect that exercise has on your weight depends on whether you are male or female rather than being independent of your sex. For example if being male means that runners weigh more than non-runners, but being female means that runners weight less than non-runners then we would say that there was an interaction.
We will first consider how to visualise the data before then carrying out an appropriate statistical test.
14.3 Data and hypotheses
We will recreate the example analysis used in the lecture. The data are stored as a .csv file called data/CS4-exercise.csv.
14.4 Summarise and visualise
exercise is a data frame with three variables; weight, sex and exercise. weight is the continuous response variable, whereas sex and exercise are the categorical predictor variables.
First, we read in the data:
exercise <- read_csv("data/CS4-exercise.csv")You can visualise the data with:
# visualise the data, sex vs weight
ggplot(exercise,
aes(x = sex, y = weight)) +
geom_boxplot()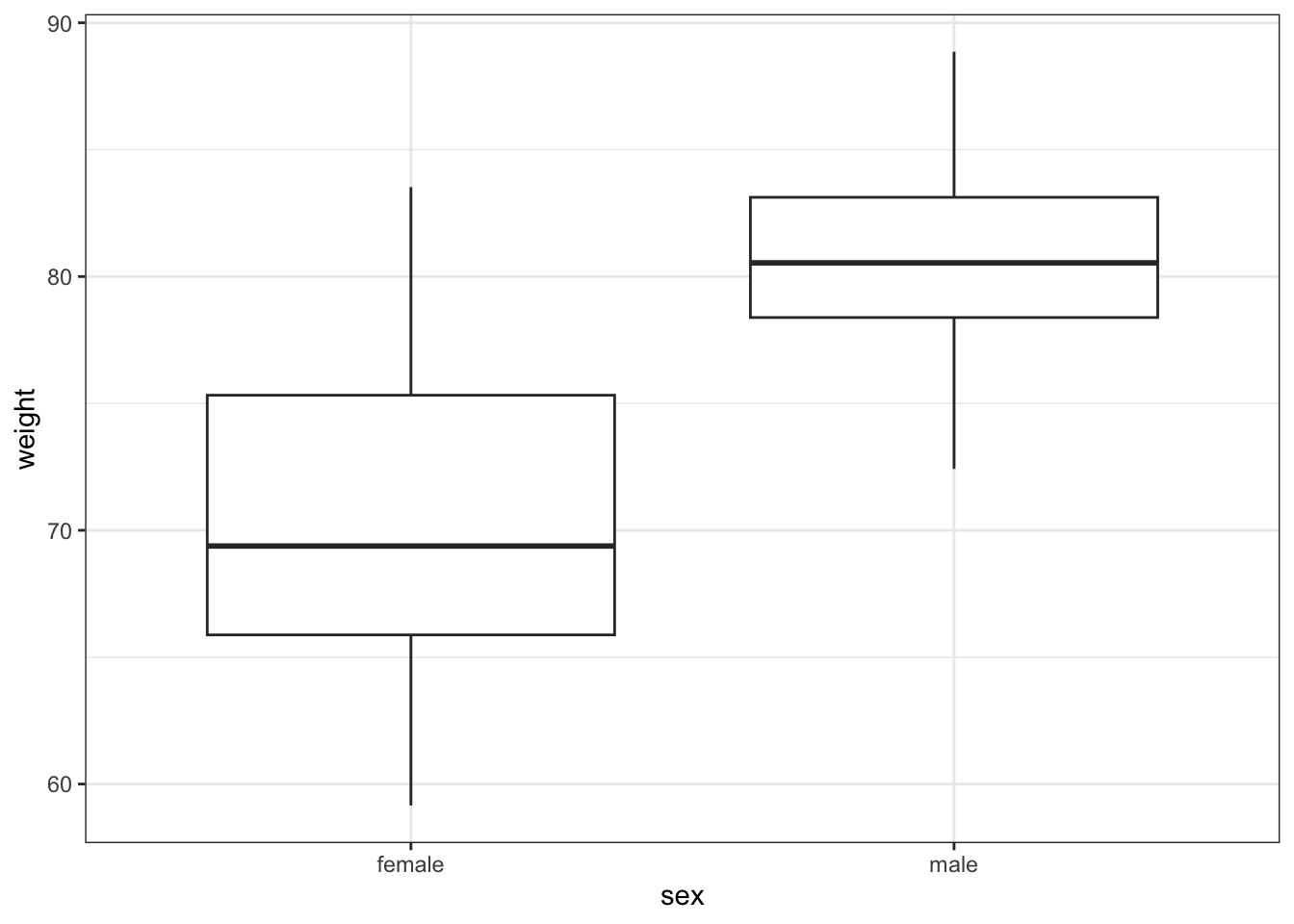
# visualise the data, exercise vs weight
ggplot(exercise,
aes(x = exercise, y = weight)) +
geom_boxplot()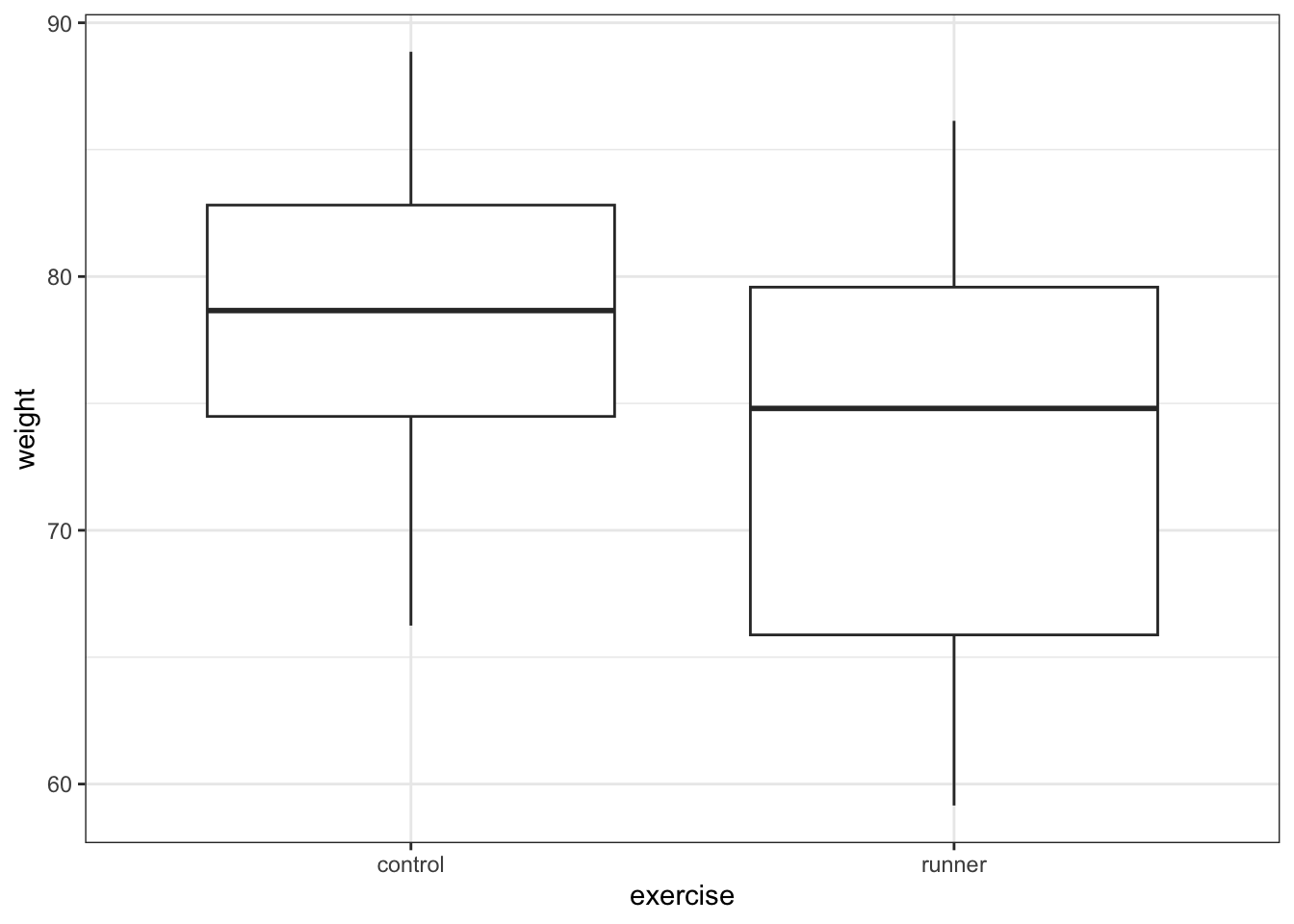
First, we read in the data:
exercise_py = pd.read_csv("data/CS4-exercise.csv")You can visualise the data with:
# visualise the data, sex vs weight
(ggplot(exercise_py,
aes(x = "sex", y = "weight")) +
geom_boxplot())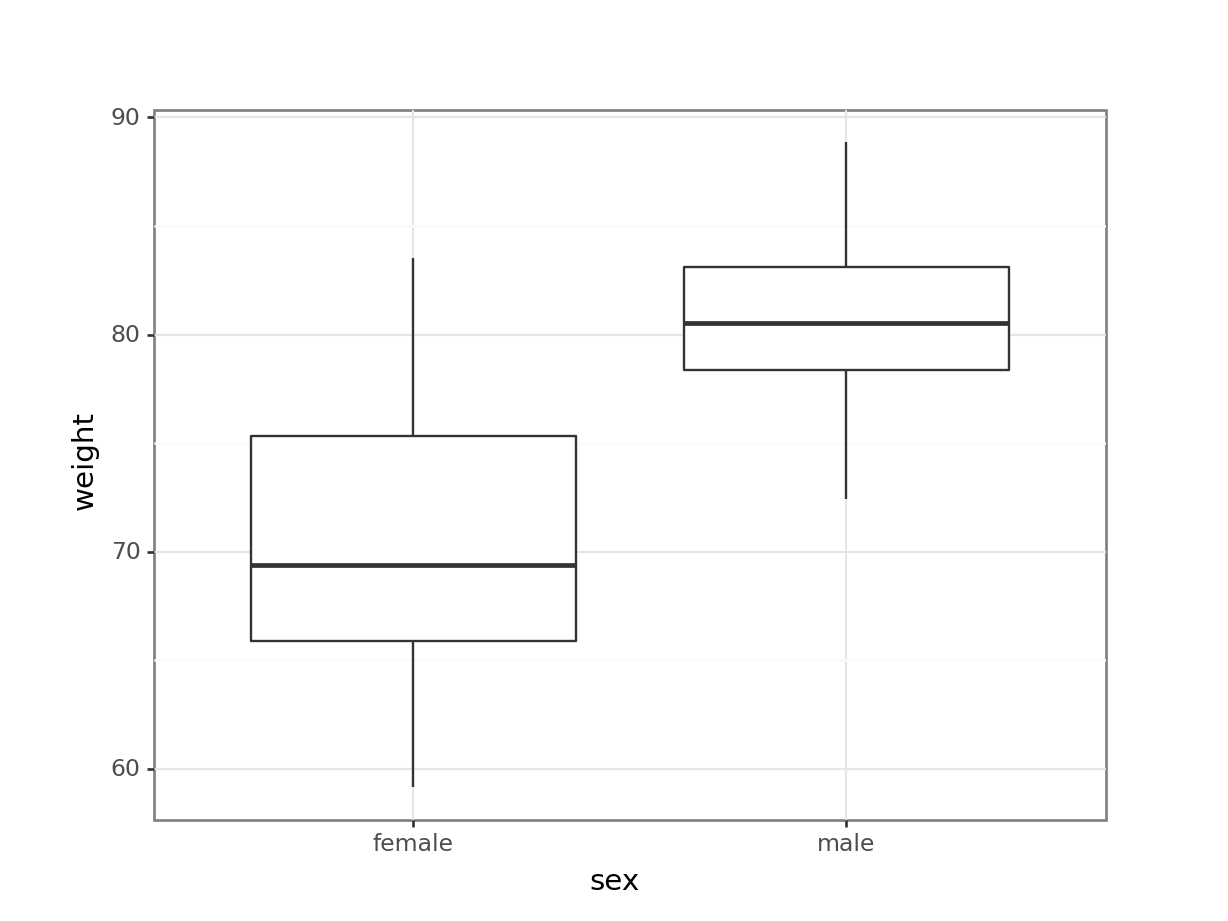
# visualise the data, exercise vs weight
(ggplot(exercise_py,
aes(x = "exercise", y = "weight")) +
geom_boxplot())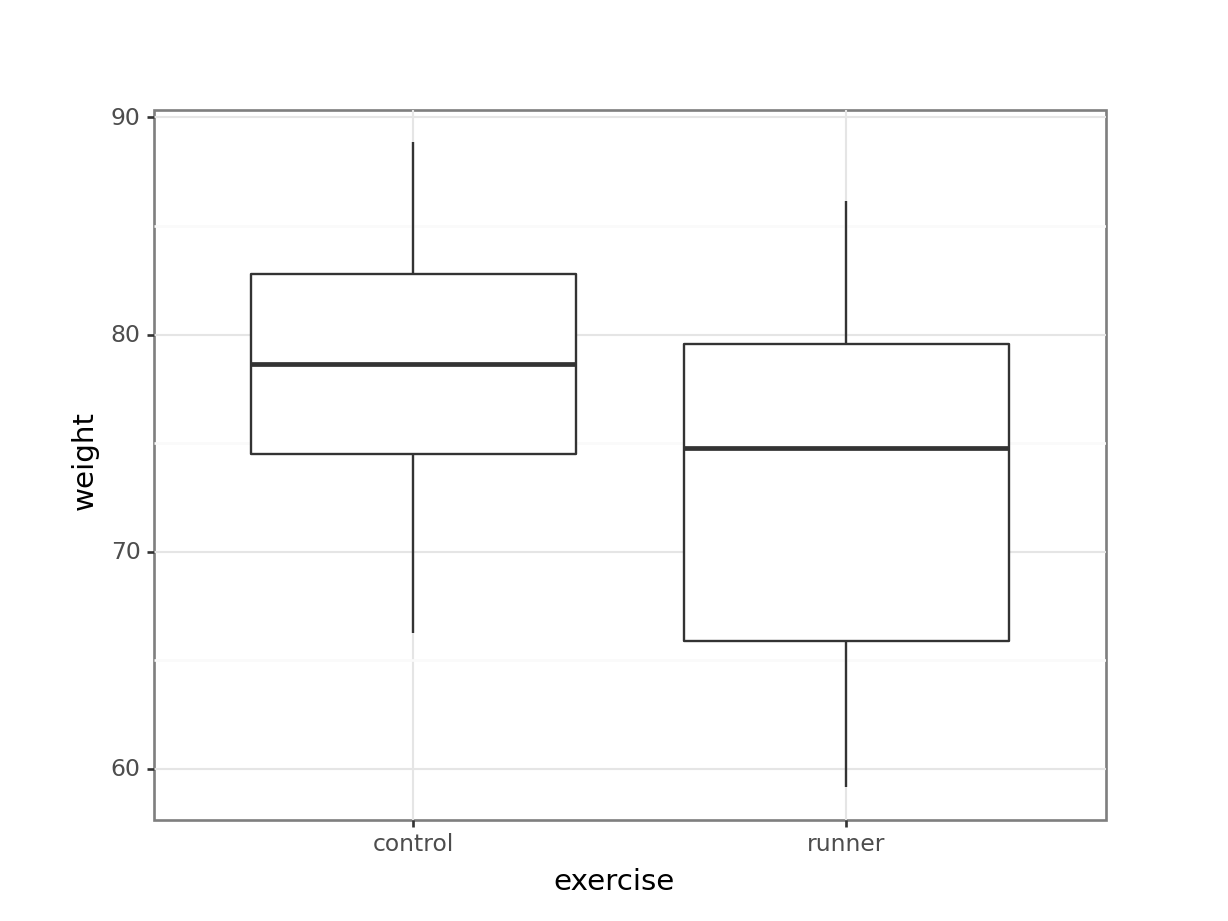
These produce box plots showing the response variable (weight) only in terms of one of the predictor variables. The values of the other predictor variable in each case aren’t taken into account.
A better way would be to visualise both variables at the same time. We can do this as follows:
ggplot(exercise,
aes(x = sex, y = weight, fill = exercise)) +
geom_boxplot() +
scale_fill_brewer(palette = "Dark2")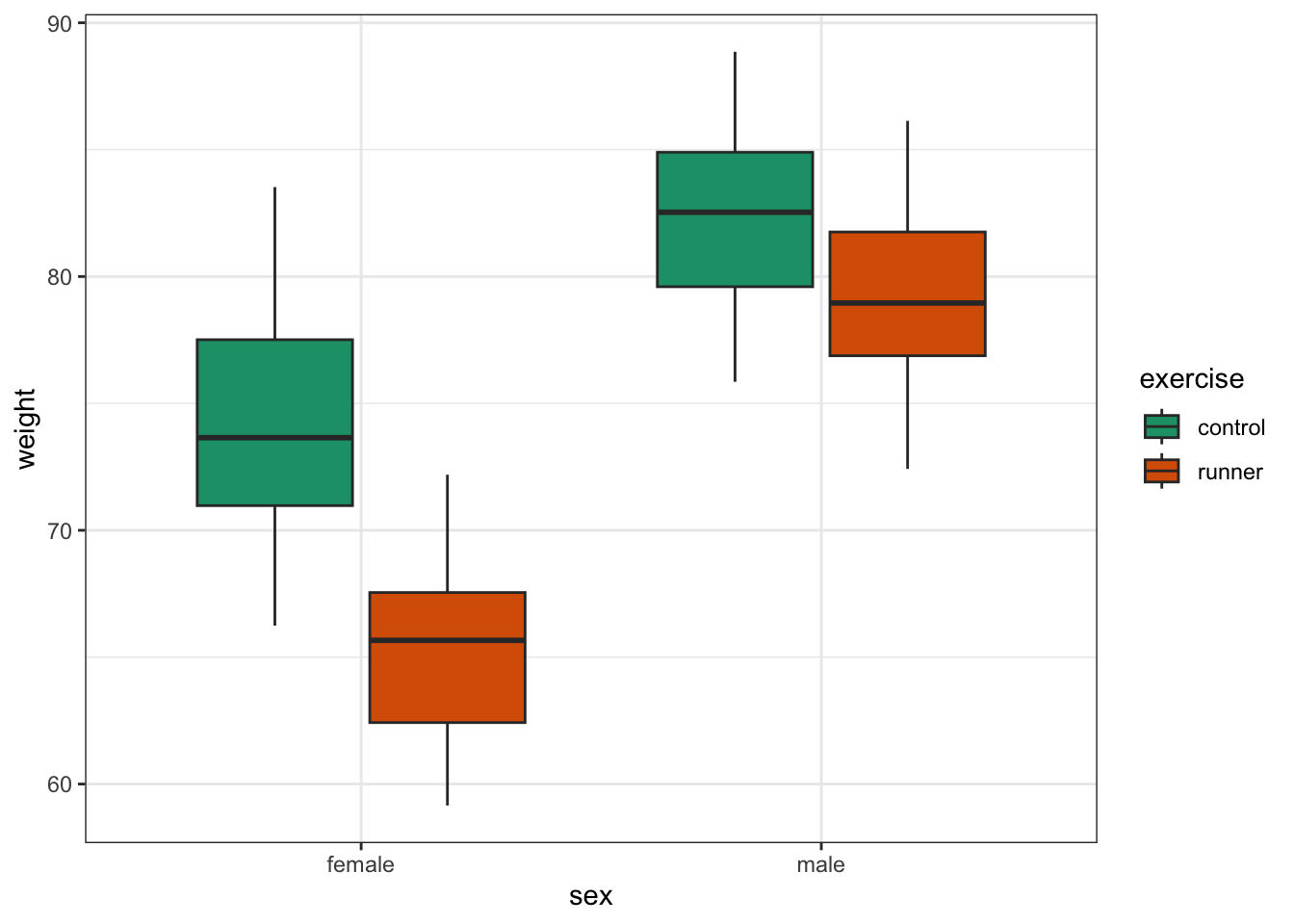
This produces box plots for all (four) combinations of the predictor variables. We are plotting sex on the x-axis; weight on the y-axis and filling the box plot by exercise regime.
Here I’ve also changed the default colouring scheme, by using scale_fill_brewer(palette = "Dark2"). This uses a colour-blind friendly colour palette (more about the Brewer colour pallete here).
(ggplot(exercise_py,
aes(x = "sex",
y = "weight", fill = "exercise")) +
geom_boxplot() +
scale_fill_brewer(type = "qual", palette = "Dark2"))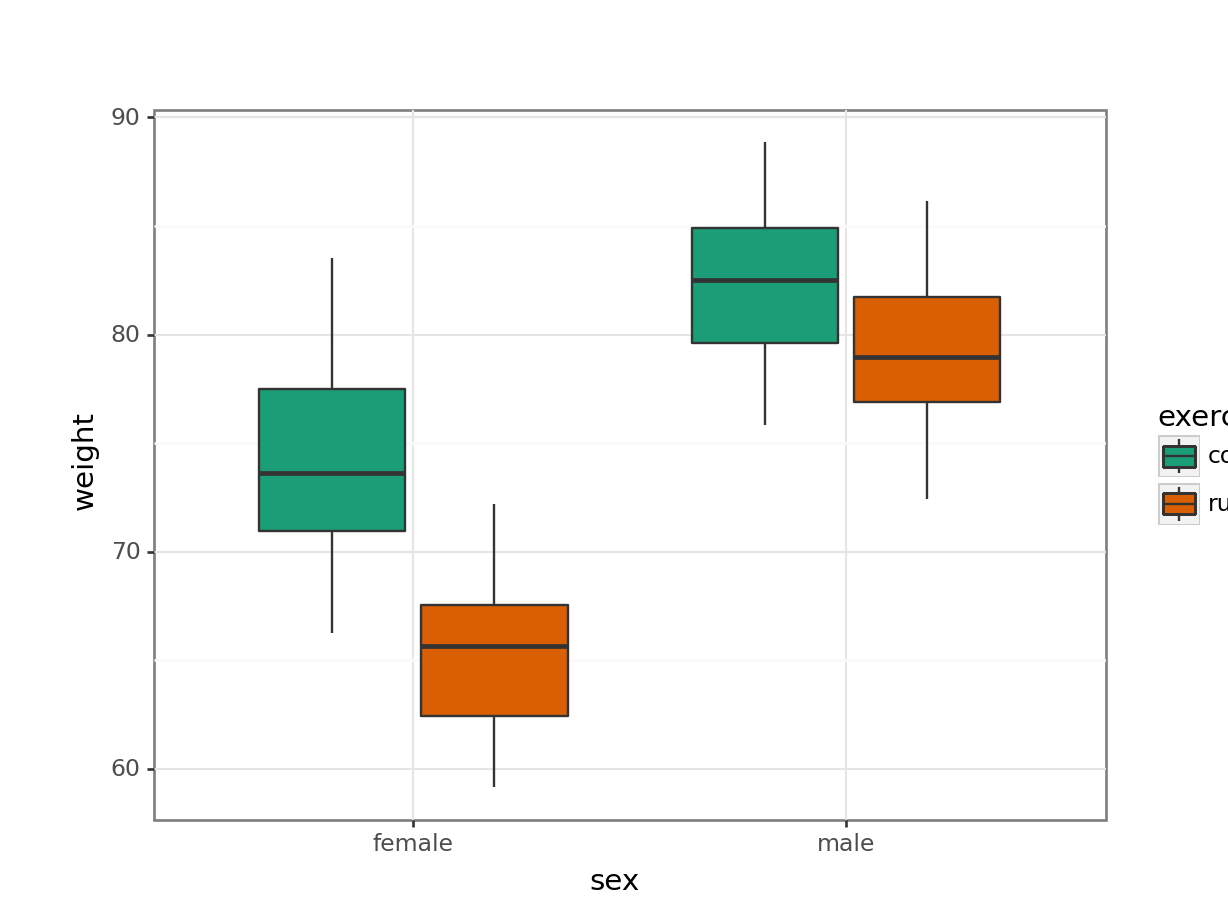
This produces box plots for all (four) combinations of the predictor variables. We are plotting sex on the x-axis; weight on the y-axis and filling the box plot by exercise regime.
Here I’ve also changed the default colouring scheme, by using scale_fill_brewer(type = "qual", palette = "Dark2"). This uses a colour-blind friendly colour palette (more about the Brewer colour pallete here).
In this example there are only four box plots and so it is relatively easy to compare them and look for any interactions between variables, but if there were more than two groups per categorical variable, it would become harder to spot what was going on.
To compare categorical variables more easily we can just plot the group means which aids our ability to look for interactions and the main effects of each predictor variable. This is called an interaction plot.
Create an interaction plot:
We’re adding a bit of jitter to the data, to avoid too much overlap between the data points. We can do this with geom_jitter().
ggplot(exercise,
aes(x = sex, y = weight,
colour = exercise, group = exercise)) +
geom_jitter(width = 0.05) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line") +
scale_colour_brewer(palette = "Dark2")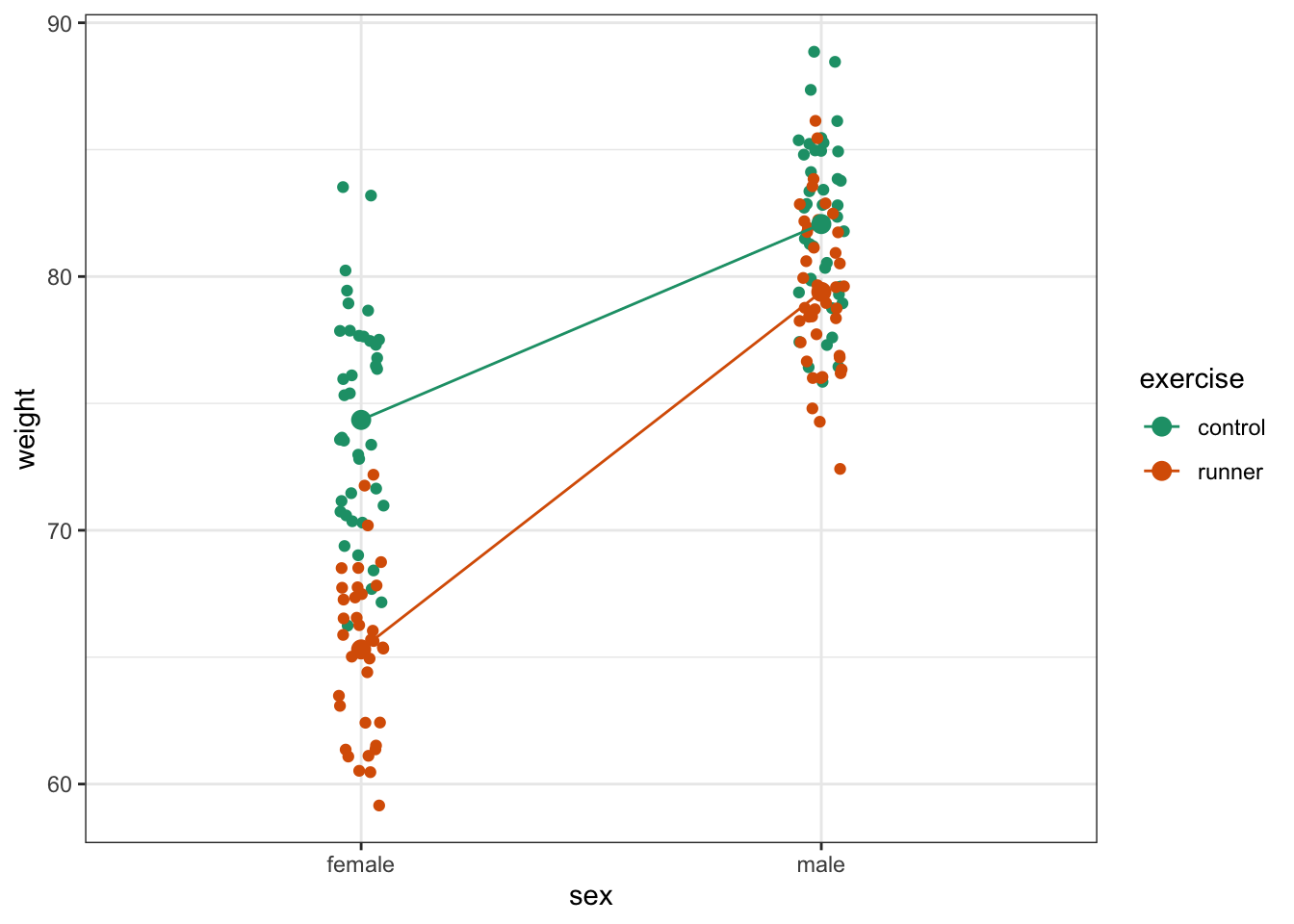
Here we plot weight on the y-axis, by sex on the x-axis.
- we
colourthe data byexerciseregime andgroupthe data byexerciseto work out the mean values of each group geom_jitter(width = 0.05)displays the data, with a tiny bit of random noise, to separate the data points a bit for visualisationstat_summary(fun = mean)calculates the mean for each groupscale_colour_brewer()lets us define the colour palette
The choice of which categorical factor is plotted on the horizontal axis and which is plotted as different lines is completely arbitrary. Looking at the data both ways shouldn’t add anything but often you’ll find that you prefer one plot to another.
Plot the interaction plot the other way round:
ggplot(exercise,
aes(x = exercise, y = weight,
colour = sex, group = sex)) +
geom_jitter(width = 0.05) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line") +
scale_colour_brewer(palette = "Dark2")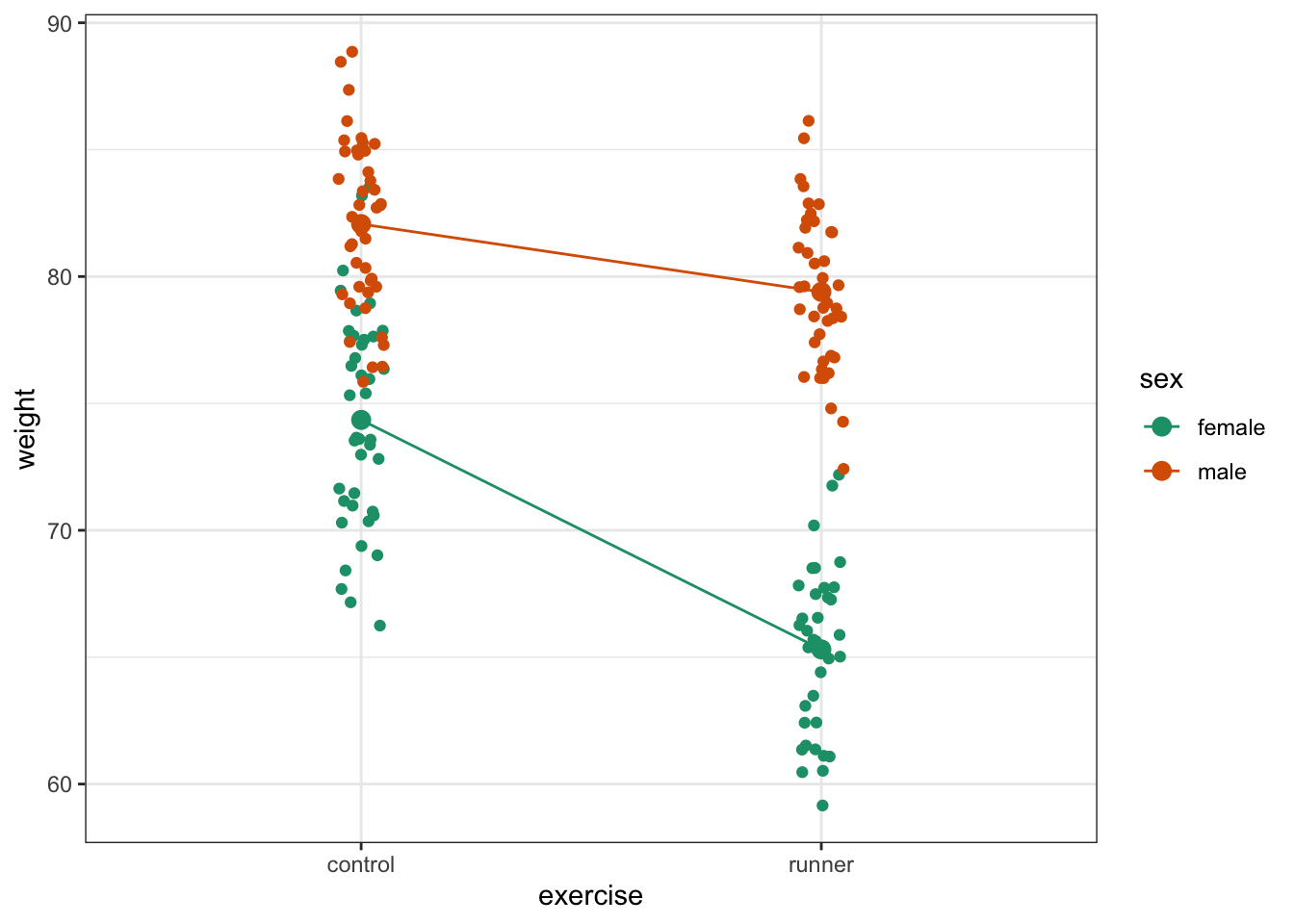
We’re adding a bit of jitter to the data, to avoid too much overlap between the data points. We can do this with geom_jitter().
(ggplot(exercise_py,
aes(x = "sex", y = "weight",
colour = "exercise", group = "exercise")) +
geom_jitter(width = 0.05) +
stat_summary(fun_data = "mean_cl_boot",
geom = "point", size = 3) +
stat_summary(fun_data = "mean_cl_boot",
geom = "line") +
scale_colour_brewer(type = "qual", palette = "Dark2"))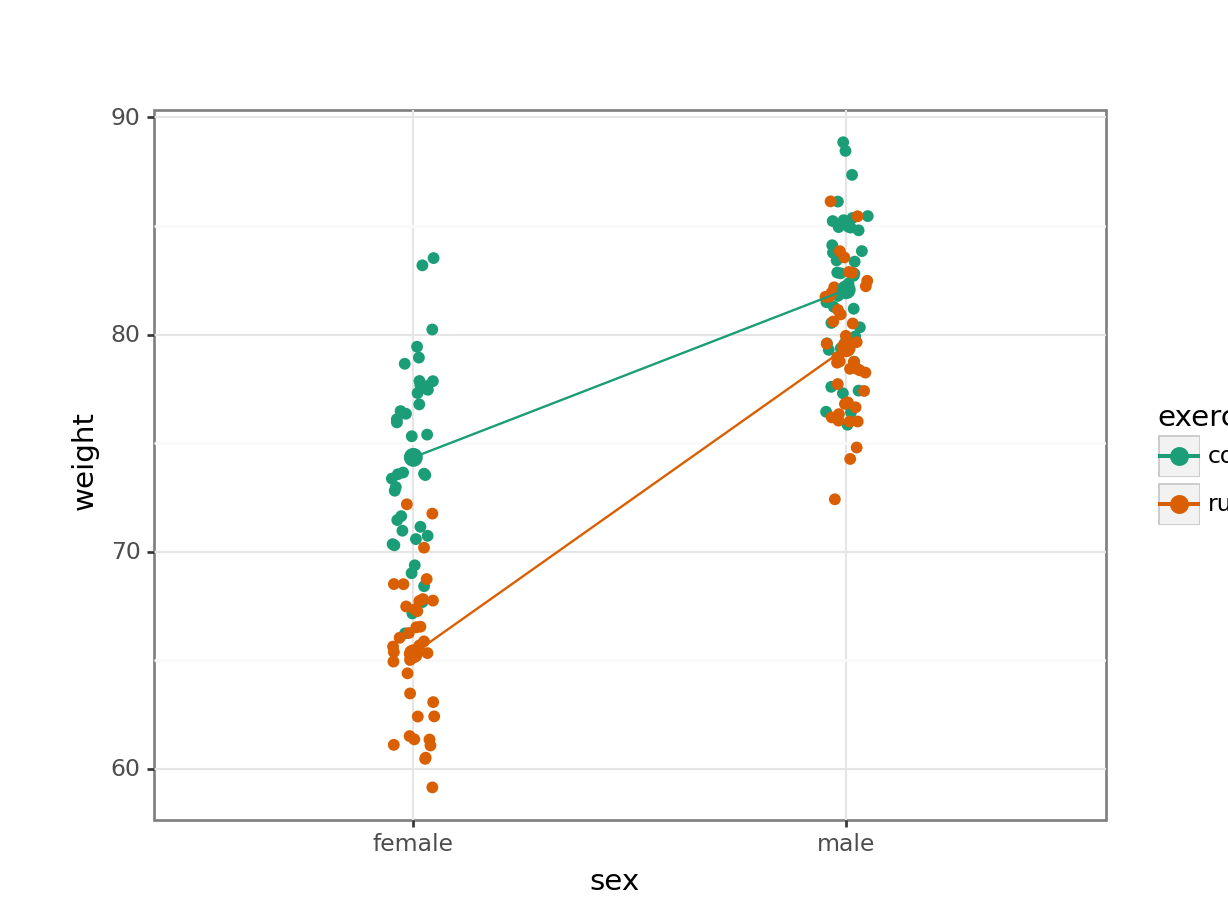
Here we plot weight on the y-axis, by sex on the x-axis.
- we
colourthe data byexerciseregime andgroupthe data byexerciseto work out the mean values of each group geom_jitter(width = 0.05)displays the data, with a tiny bit of random noise, to separate the data points a bit for visualisationstat_summary(fun_data = "mean_cl_boot")calculates the mean for each groupscale_colour_brewer()lets us define the colour palette
The choice of which categorical factor is plotted on the horizontal axis and which is plotted as different lines is completely arbitrary. Looking at the data both ways shouldn’t add anything but often you’ll find that you prefer one plot to another.
Plot the interaction plot the other way round:
(ggplot(exercise_py,
aes(x = "exercise", y = "weight",
colour = "sex", group = "sex")) +
geom_jitter(width = 0.05) +
stat_summary(fun_data = "mean_cl_boot",
geom = "point", size = 3) +
stat_summary(fun_data = "mean_cl_boot",
geom = "line") +
scale_colour_brewer(type = "qual", palette = "Dark2"))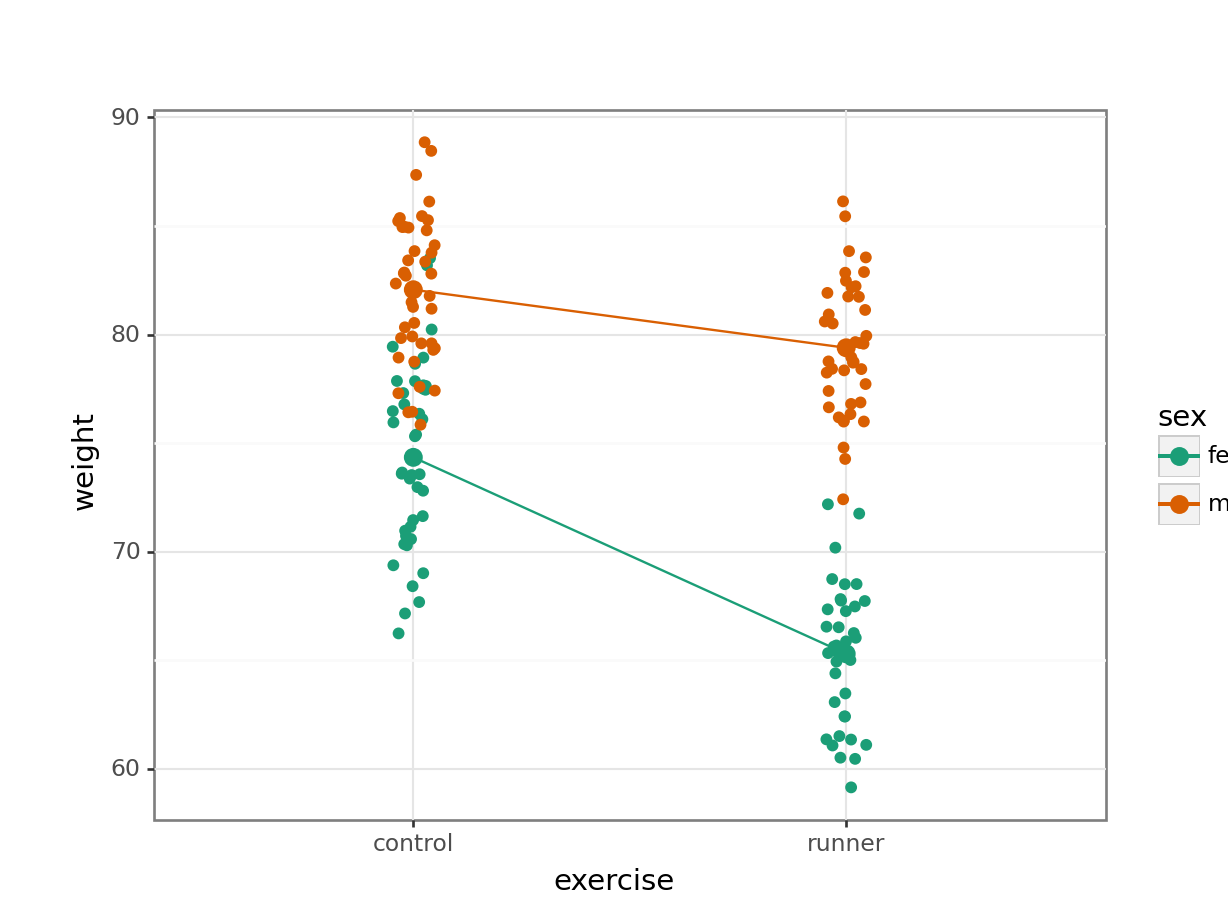
By now you should have a good feeling for the data and could already provide some guesses to the following three questions:
- Does there appear to be any interaction between the two categorical variables?
- If not:
- Does
exercisehave an effect onweight? - Does
sexhave an effect onweight?
- Does
We can now attempt to answer these three questions more formally using an ANOVA test. We have to test for three things: the interaction, the effect of exercise and the effect of sex.
14.5 Assumptions
Before we can formally test these things we first need to define the model and check the underlying assumptions. We use the following code to define the model:
# define the linear model
lm_exercise <- lm(weight ~ sex + exercise + sex:exercise,
data = exercise)The sex:exercise term is how R represents the concept of an interaction between these two variables.
# create a linear model
model = smf.ols(formula = "weight ~ exercise * sex", data = exercise_py)
# and get the fitted parameters of the model
lm_exercise_py = model.fit()The formula weight ~ exercise * sex can be read as “weight depends on exercise and sex and the interaction between exercise and sex.
As the two-way ANOVA is a type of linear model we need to satisfy pretty much the same assumptions as we did for a simple linear regression or a one-way ANOVA:
- The data must not have any systematic pattern to it
- The residuals must be normally distributed
- The residuals must have homogeneity of variance
- The fit should not depend overly much on a single point (no point should have high leverage).
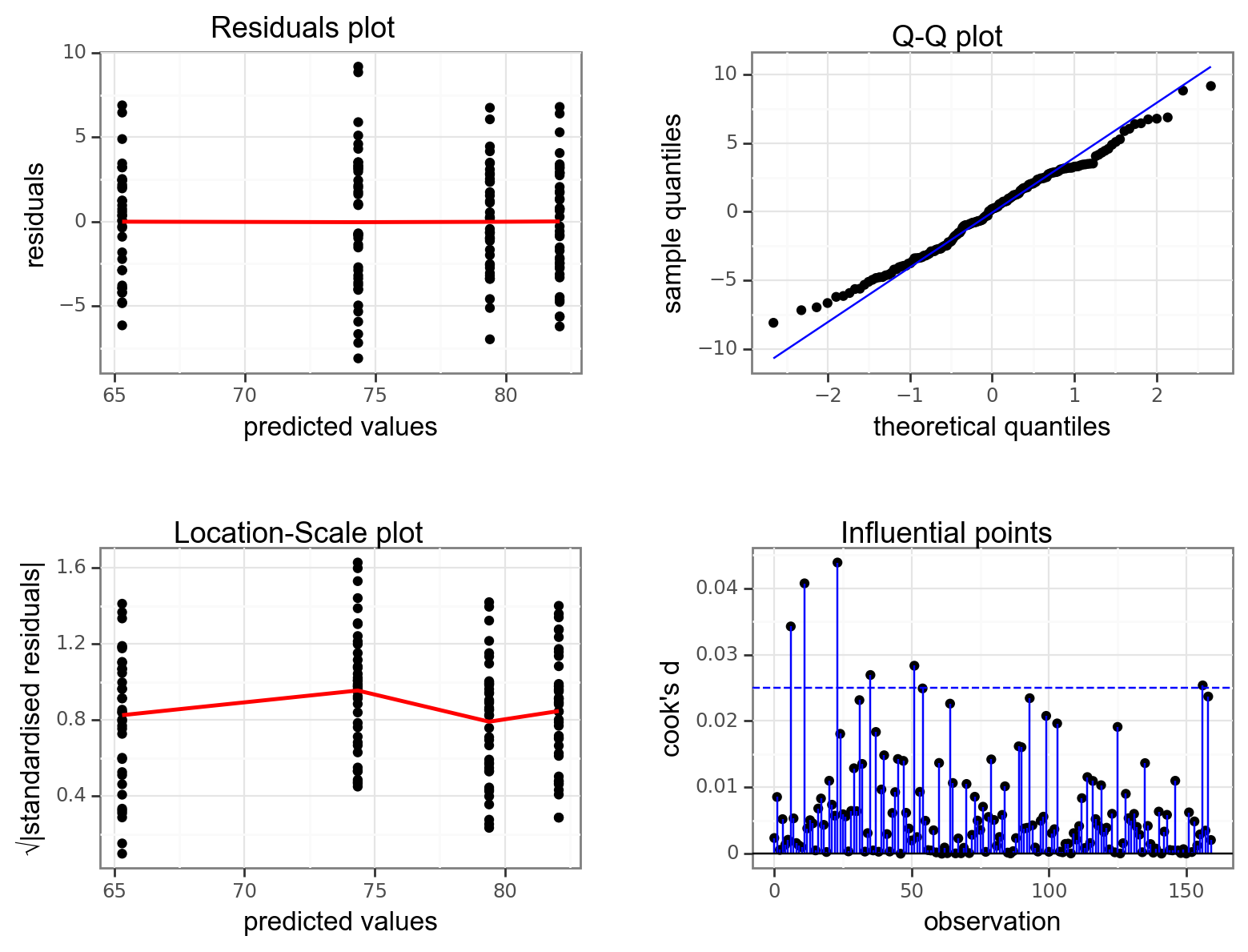
Again, we will check these assumptions visually by producing four key diagnostic plots.
resid_panel(lm_exercise,
plots = c("resid", "qq", "ls", "cookd"),
smoother = TRUE)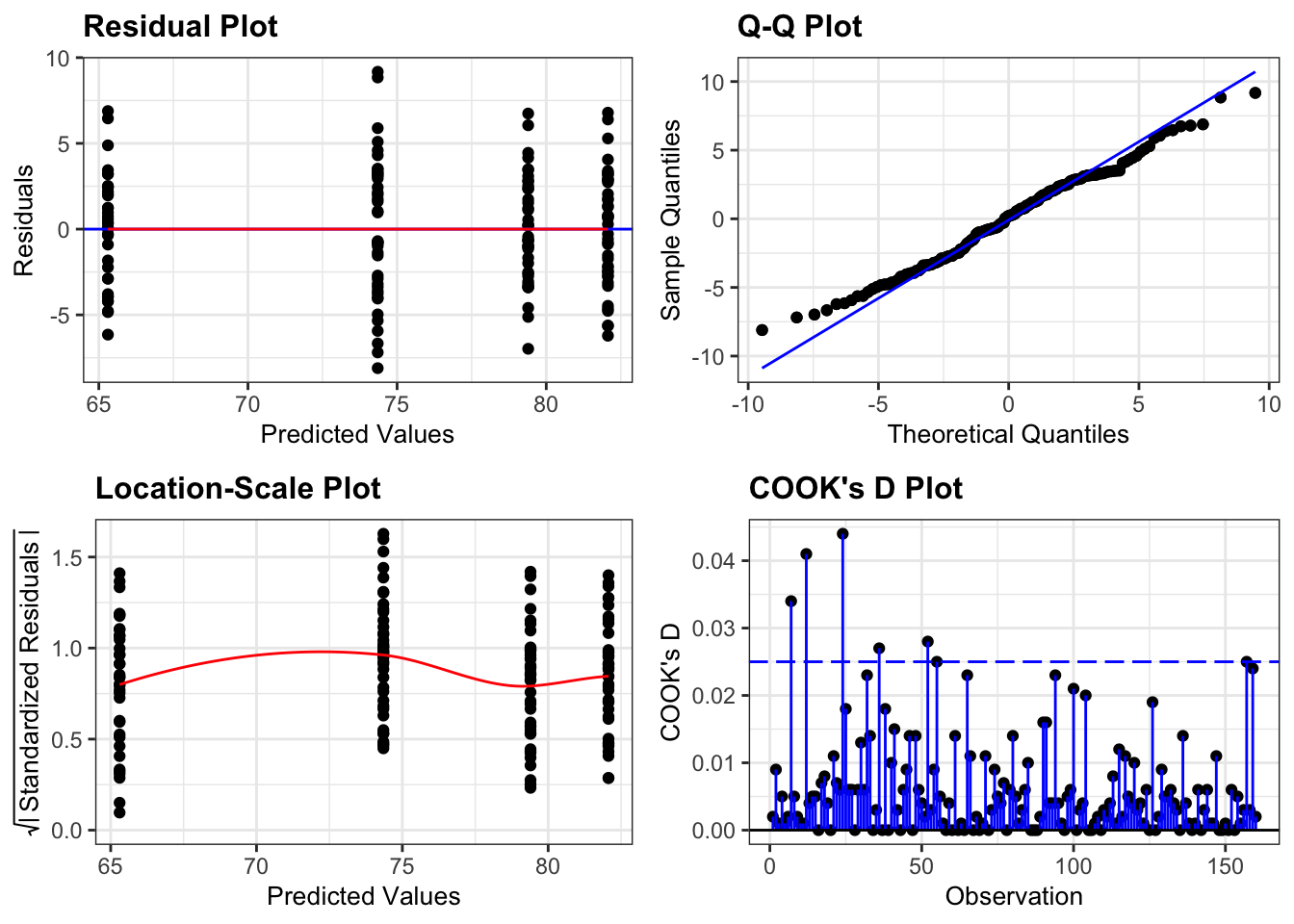
- The Residual plot shows the residuals against the predicted values. There is no systematic pattern here and this plot is pretty good.
- The Q-Q plot allows a visual inspection of normality. Again, this looks OK (not perfect but OK).
- The Location-Scale plot allows us to investigate whether there is homogeneity of variance. This plot is fine (not perfect but fine).
- The Cook’s D plot shows that no individual point has a high influence on the model (all values are well below 0.5)
There is a shorthand way of writing:
weight ~ sex + exercise + sex:exercise
If you use the following syntax:
weight ~ sex * exercise
Then R interprets it exactly the same way as writing all three terms. You can see this if you compare the output of the following two commands:
anova(lm(weight ~ sex + exercise + sex:exercise,
data = exercise))Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
sex 1 4510.1 4510.1 366.911 < 2.2e-16 ***
exercise 1 1312.0 1312.0 106.733 < 2.2e-16 ***
sex:exercise 1 404.4 404.4 32.902 4.889e-08 ***
Residuals 156 1917.6 12.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1anova(lm(weight ~ sex * exercise,
data = exercise))Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
sex 1 4510.1 4510.1 366.911 < 2.2e-16 ***
exercise 1 1312.0 1312.0 106.733 < 2.2e-16 ***
sex:exercise 1 404.4 404.4 32.902 4.889e-08 ***
Residuals 156 1917.6 12.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1dgplots(lm_exercise_py)
14.6 Implement and interpret test
The assumptions appear to be met well enough, meaning we can implement the ANOVA. We do this as follows (this is probably the easiest bit!):
# perform the ANOVA
anova(lm_exercise)Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
sex 1 4510.1 4510.1 366.911 < 2.2e-16 ***
exercise 1 1312.0 1312.0 106.733 < 2.2e-16 ***
sex:exercise 1 404.4 404.4 32.902 4.889e-08 ***
Residuals 156 1917.6 12.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1We have a row in the table for each of the different effects that we’ve asked R to consider. The last column is the important one as this contains the p-values. We need to look at the interaction row first.
sm.stats.anova_lm(lm_exercise_py, typ = 2) sum_sq df F PR(>F)
exercise 1311.970522 1.0 106.733448 2.177106e-19
sex 4636.450232 1.0 377.191645 1.760076e-43
exercise:sex 404.434414 1.0 32.902172 4.889216e-08
Residual 1917.556353 156.0 NaN NaNWe have a row in the table for each of the different effects that we’ve asked Python to consider. The last column is the important one as this contains the p-values. We need to look at the interaction row first.
sex:exercise has a p-value of about 4.89e-08 (which is smaller than 0.05) and so we can conclude that the interaction between sex and exercise is significant.
This is where we must stop.
The top two lines (corresponding to the effects of sex and exercise) are meaningless now. This is because the interaction means that we cannot interpret the main effects independently.
In this case, weight depends on and the sex and the exercise regime. This means the effect of sex on weight is dependent on exercise (and vice-versa).
We would report this as follows:
A two-way ANOVA test showed that there was a significant interaction between the effects of sex and exercise on weight (p = 4.89e-08). Exercise was associated with a small loss of weight in males but a larger loss of weight in females.
14.7 Exercises
14.7.1 Auxin response
Exercise
Level:
Plant height responses to auxin in different genotypes
These data/CS4-auxin.csv data are from a simulated experiment that looks at the effect of the plant hormone auxin on plant height.
The experiment consists of two genotypes: a wild type control and a mutant (genotype). The plants are treated with auxin at different concentrations: none, low and high, which are stored in the concentration column.
The response variable plant height (plant_height) is then measured at the end of their life cycle, in centimeters.
Questions to answer:
- Visualise the data using boxplots and interaction plots.
- Does there appear to be any interaction between
genotypeandconcentration? - Carry out a two-way ANOVA test.
- Check the assumptions.
- What can you conclude? (Write a sentence to summarise).
Answer
14.8 Answer
Load the data
# read in the data
auxin_response <- read_csv("data/CS4-auxin.csv")
# let's have a peek at the data
head(auxin_response)# A tibble: 6 × 3
genotype concentration plant_height
<chr> <chr> <dbl>
1 control high 33.7
2 control high 27.1
3 control high 22.9
4 control high 28.7
5 control high 30.7
6 control high 26.9Visualise the data
ggplot(auxin_response,
aes(x = genotype, y = plant_height)) +
geom_boxplot()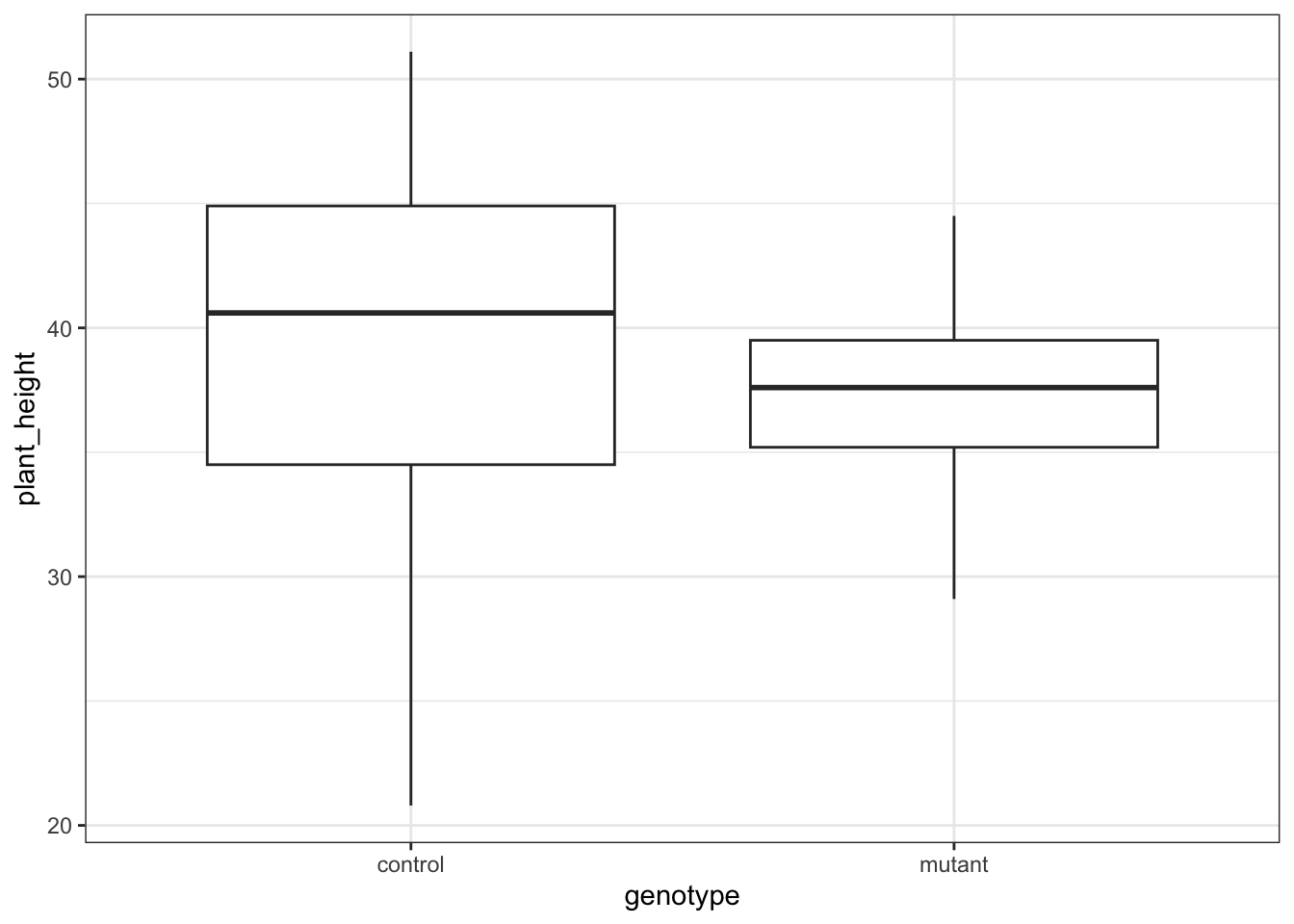
ggplot(auxin_response,
aes(x = concentration, y = plant_height)) +
geom_boxplot()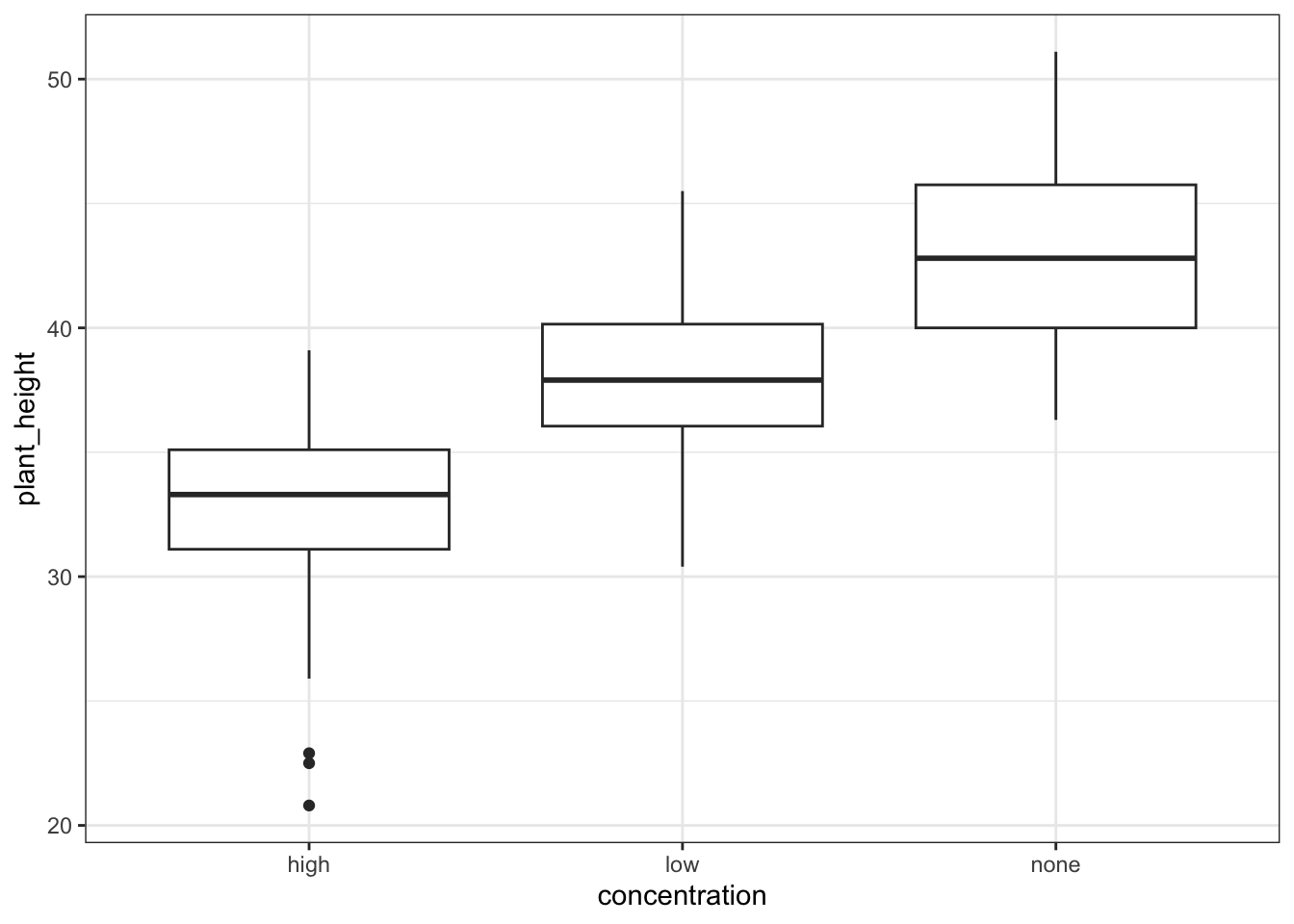
Let’s look at the interaction plots. We’re only plotting the mean values here, but feel free to explore the data itself by adding another geom_.
# by genotype
ggplot(auxin_response,
aes(x = concentration,
y = plant_height,
colour = genotype, group = genotype)) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(palette = "Dark2")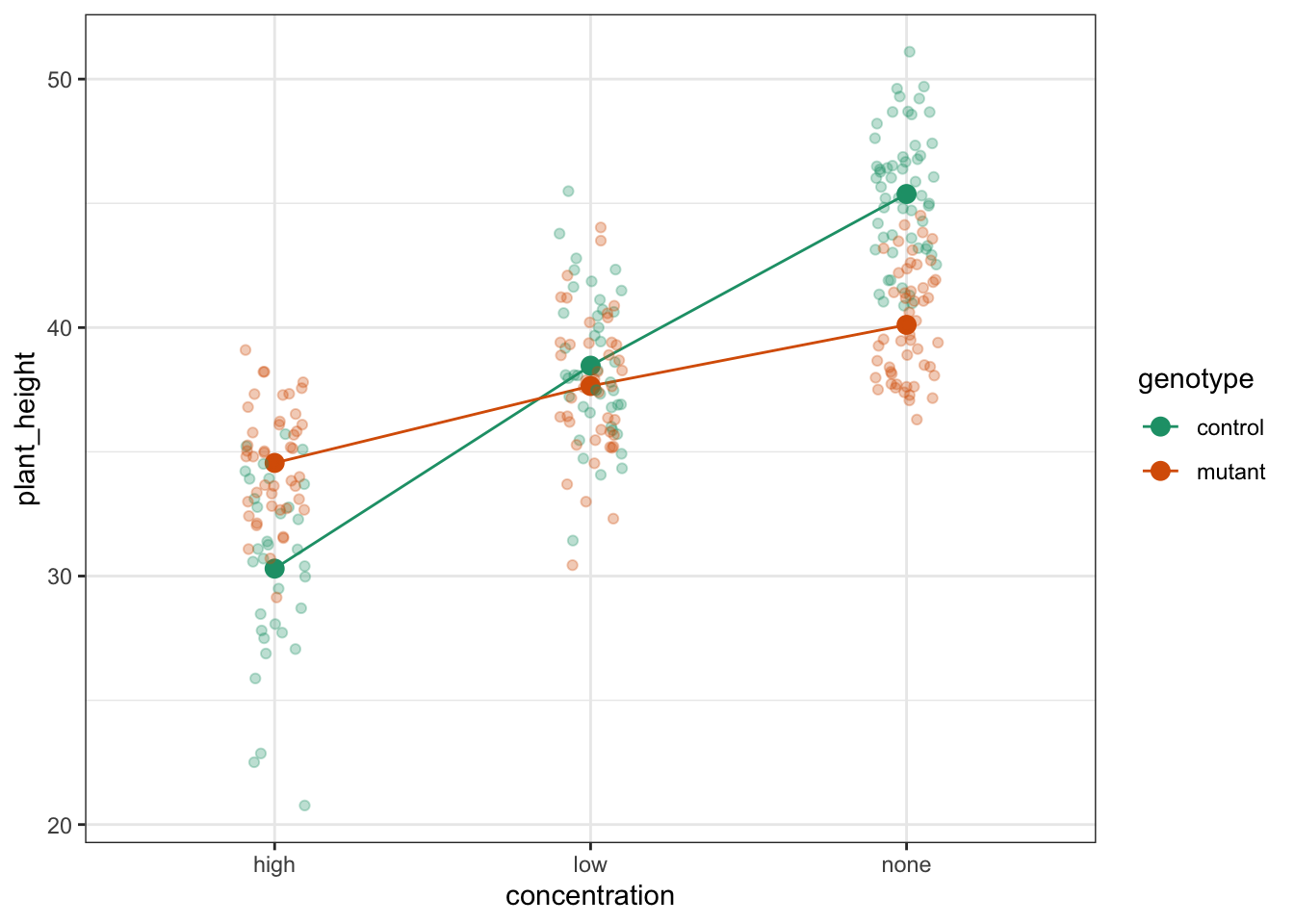
# by concentration
ggplot(auxin_response,
aes(x = genotype,
y = plant_height,
colour = concentration, group = concentration)) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(palette = "Dark2")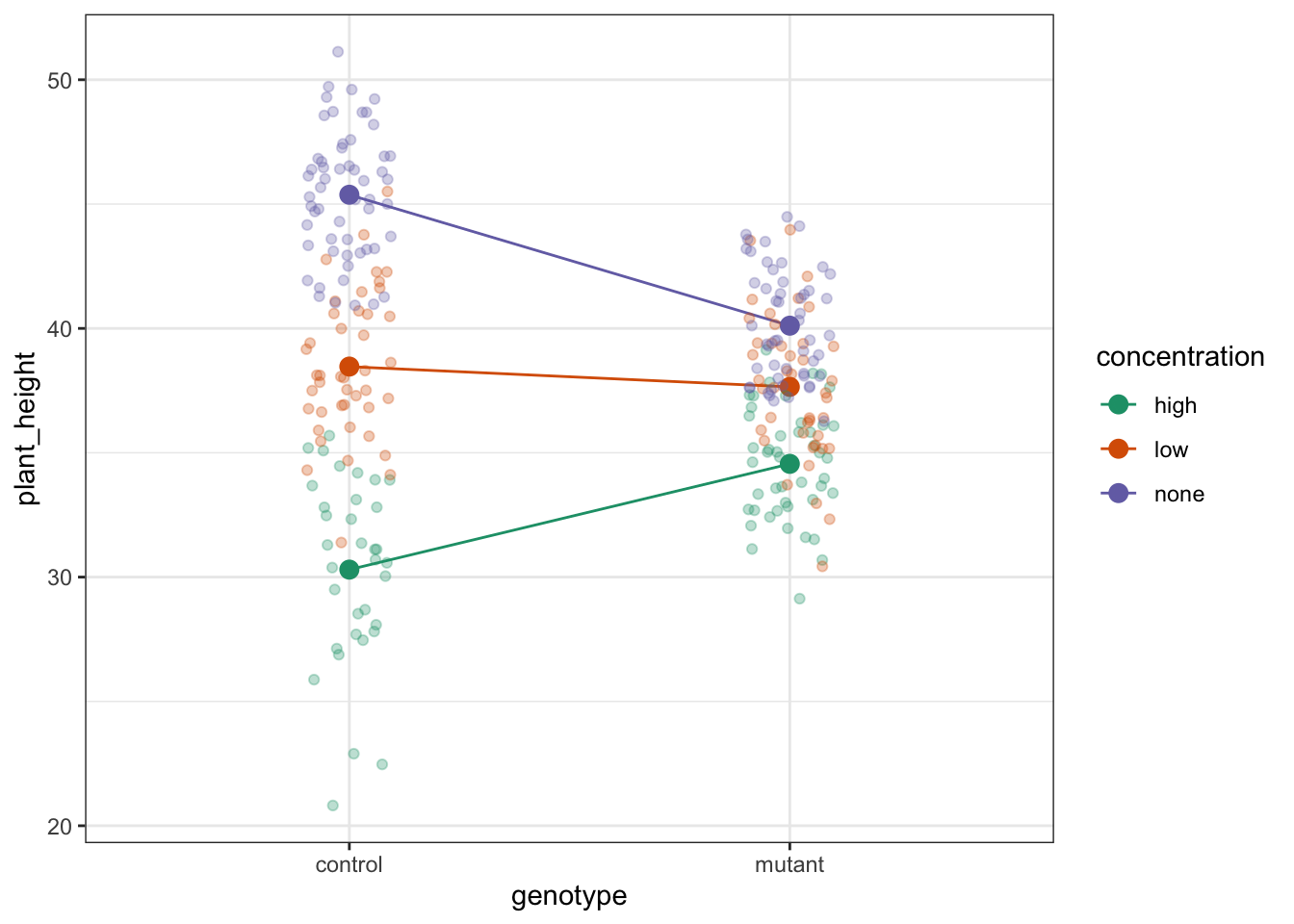
We’ve constructed both box plots and two interaction plots. We only needed to do one interaction plot but I find it can be quite useful to look at the data from different angles.
The interaction plots show the mean values for each group, so I prefer to overlay this with the actual data. Both interaction plots suggest that there is an interaction here as the lines in the plots aren’t parallel. Looking at the interaction plot with concentration on the x-axis, it appears that there is non-difference between genotypes when the concentration is low, but that there is a difference between genotypes when the concentration is none or high.
Assumptions
First we need to define the model:
# define the linear model, with interaction term
lm_auxin <- lm(plant_height ~ concentration * genotype,
data = auxin_response)Next, we check the assumptions:
resid_panel(lm_auxin,
plots = c("resid", "qq", "ls", "cookd"),
smoother = TRUE)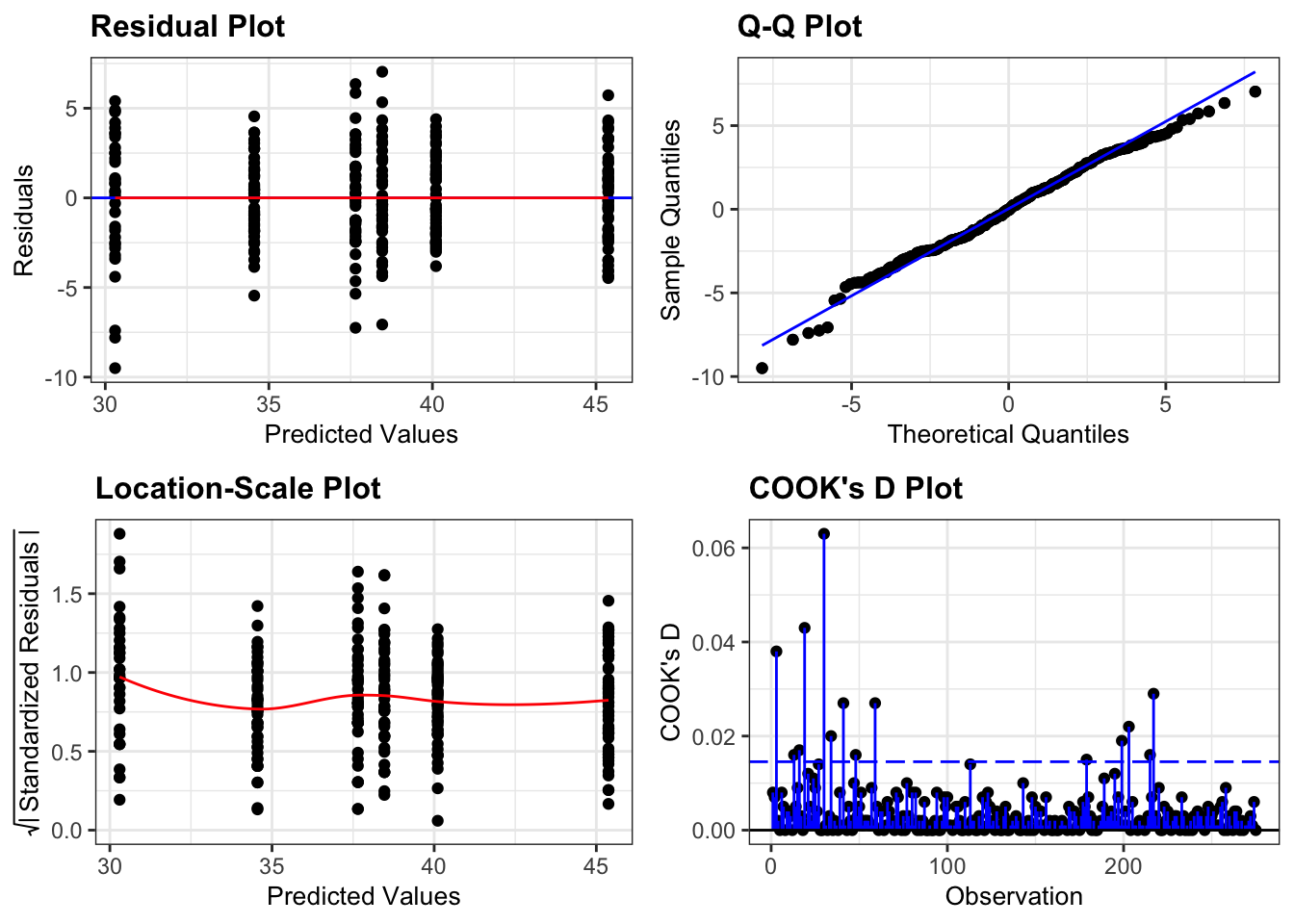
So, these actually all look pretty good, with the data looking normally distributed (Q-Q plot), linearity OK (Residual plot), homogeneity of variance looking sharp (Location-scale plot) and no clear influential points (Cook’s D plot).
Implement the test
Let’s carry out a two-way ANOVA:
# perform the ANOVA
anova(lm_auxin)Analysis of Variance Table
Response: plant_height
Df Sum Sq Mean Sq F value Pr(>F)
concentration 2 4708.2 2354.12 316.333 < 2.2e-16 ***
genotype 1 83.8 83.84 11.266 0.0009033 ***
concentration:genotype 2 1034.9 517.45 69.531 < 2.2e-16 ***
Residuals 269 2001.9 7.44
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interpret the output and report the results
There is a significant interaction between concentration and genotype.
Load the data
# read in the data
auxin_response_py = pd.read_csv("data/CS4-auxin.csv")
# let's have a peek at the data
auxin_response_py.head() genotype concentration plant_height
0 control high 33.7
1 control high 27.1
2 control high 22.9
3 control high 28.7
4 control high 30.7Visualise the data
(ggplot(auxin_response_py,
aes(x = "genotype", y = "plant_height")) +
geom_boxplot())
(ggplot(auxin_response_py,
aes(x = "concentration", y = "plant_height")) +
geom_boxplot())
Let’s look at the interaction plots. We’re also including the data itself here with geom_jitter().
# by genotype
(ggplot(auxin_response_py,
aes(x = "concentration",
y = "plant_height",
colour = "genotype", group = "genotype")) +
stat_summary(fun_data = "mean_cl_boot",
geom = "point", size = 3) +
stat_summary(fun_data = "mean_cl_boot",
geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(type = "qual", palette = "Dark2"))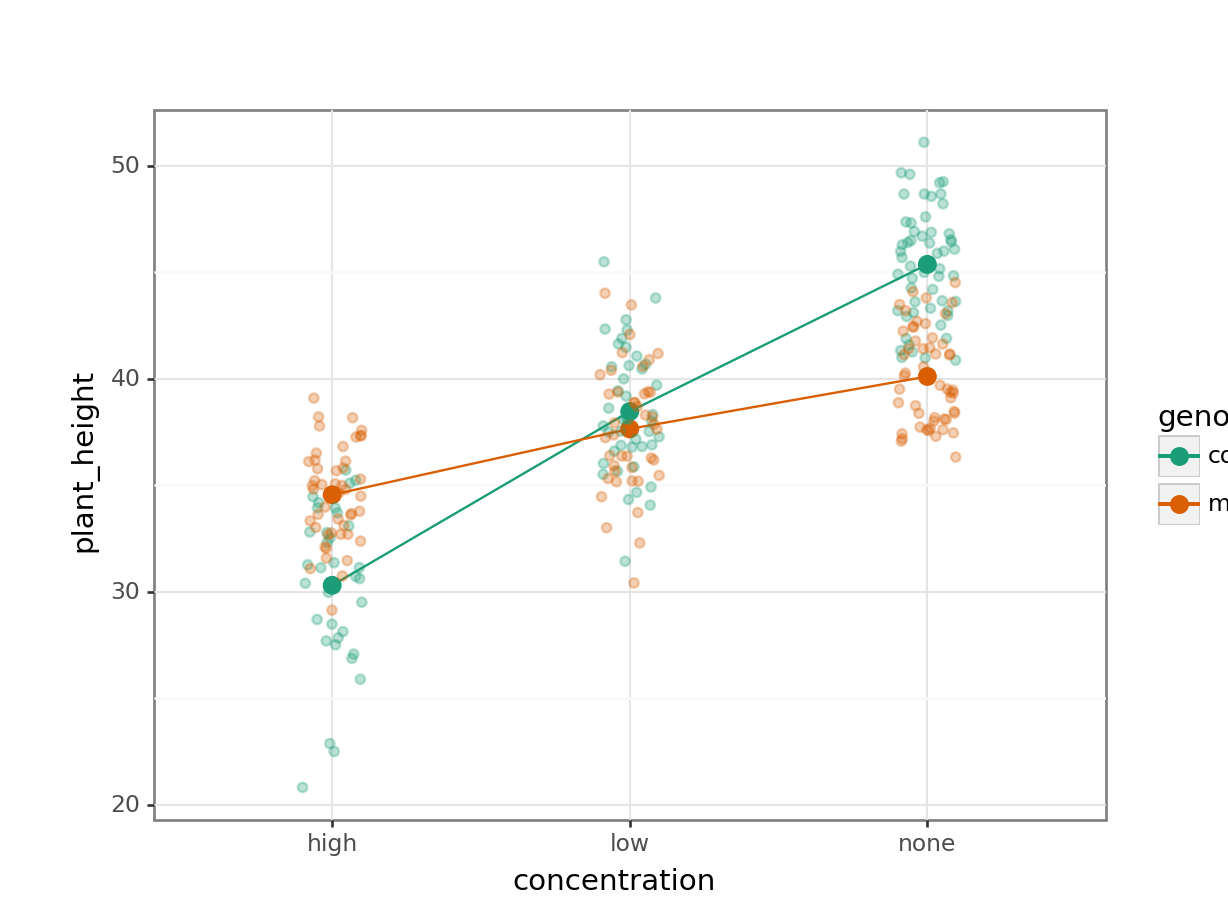
# by concentration
(ggplot(auxin_response_py,
aes(x = "genotype",
y = "plant_height",
colour = "concentration", group = "concentration")) +
stat_summary(fun_data = "mean_cl_boot",
geom = "point", size = 3) +
stat_summary(fun_data = "mean_cl_boot",
geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(type = "qual", palette = "Dark2"))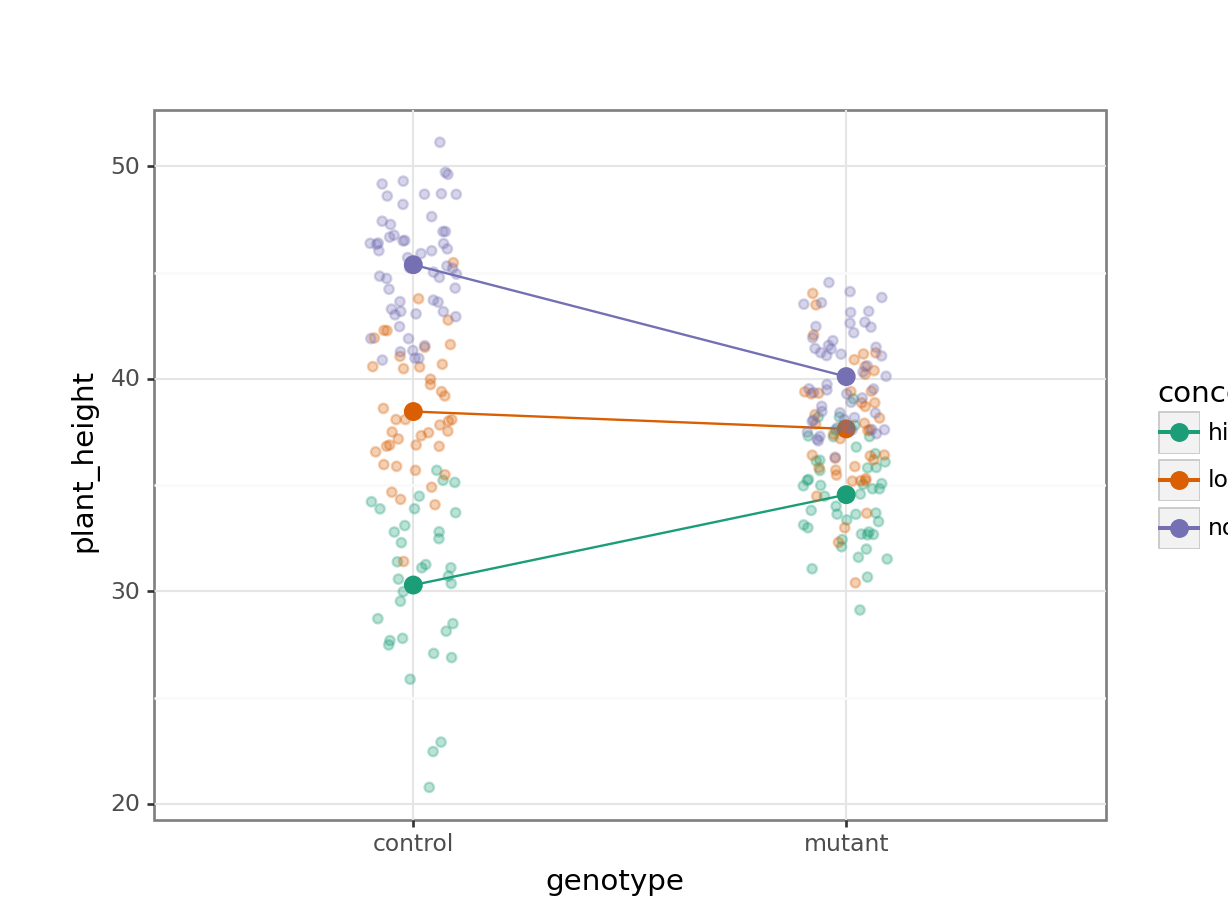
We’ve constructed both box plots and two interaction plots. We only needed to do one interaction plot but I find it can be quite useful to look at the data from different angles.
The interaction plots show the mean values for each group, so I prefer to overlay this with the actual data. Both interaction plots suggest that there is an interaction here as the lines in the plots aren’t parallel. Looking at the interaction plot with concentration on the x-axis, it appears that there is non-difference between genotypes when the concentration is low, but that there is a difference between genotypes when the concentration is none or high.
Assumptions
First we need to define the model:
# create a linear model
model = smf.ols(formula= "plant_height ~ C(genotype) * concentration", data = auxin_response_py)
# and get the fitted parameters of the model
lm_auxin_py = model.fit()Next, we check the assumptions:
dgplots(lm_auxin_py)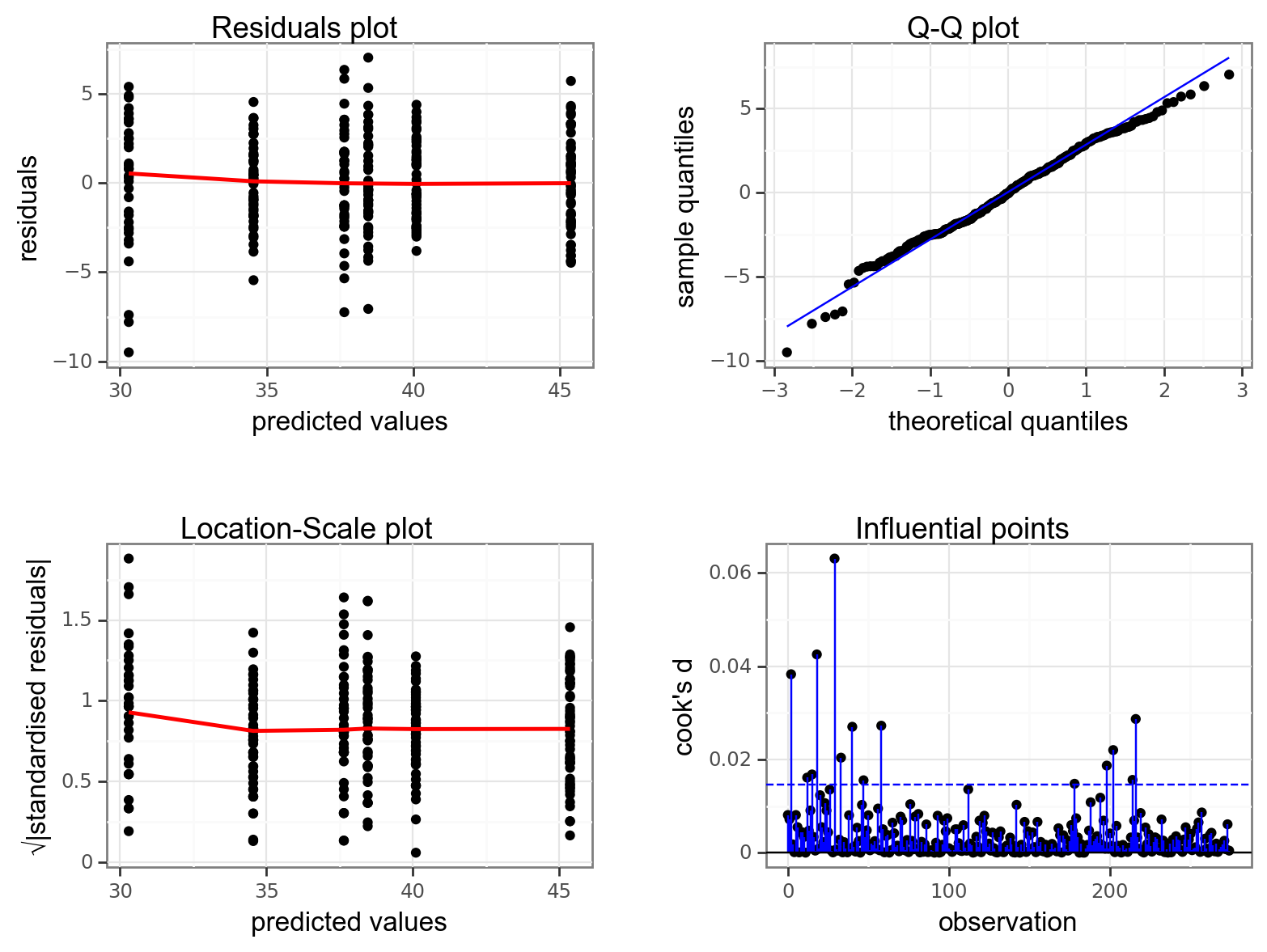
So, these actually all look pretty good, with the data looking normally distributed (Q-Q plot), linearity OK (Residual plot), homogeneity of variance looking sharp (Location-scale plot) and no clear influential points (Influential points plot).
Implement the test
Let’s carry out a two-way ANOVA:
sm.stats.anova_lm(lm_auxin_py, typ = 2) sum_sq df F PR(>F)
C(genotype) 83.839560 1.0 11.265874 9.033241e-04
concentration 4578.890410 2.0 307.642376 3.055198e-70
C(genotype):concentration 1034.894263 2.0 69.531546 4.558874e-25
Residual 2001.872330 269.0 NaN NaNInterpret the output and report the results
There is definitely a significant interaction between concentration and genotype.
So, we can conclude the following:
A two-way ANOVA showed that there is a significant interaction between genotype and auxin concentration on plant height (p = 4.56e-25). Increasing auxin concentration appears to result in a reduction of plant height in both wild type and mutant genotypes. The response in the mutant genotype seems to be less pronounced than in wild type.
14.8.1 Tulips
Exercise
Level:
Blooms and growing conditions
We’re sticking with the plant theme and using the data/CS4-tulip.csv data set, which contains information on an experiment to determine the best conditions for growing tulips (well someone has to care about these sorts of things!). The average number of flower heads (blooms) were recorded for 27 different plots. Each plot experienced one of three different watering regimes and one of three different shade regimes.
- Investigate how the number of blooms is affected by different growing conditions.
Note: have a look at the data and make sure that they are in the correct format!
Answer
Load the data
# read in the data
tulip <- read_csv("data/CS4-tulip.csv")Rows: 27 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (3): water, shade, blooms
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# have a quick look at the data
tulip# A tibble: 27 × 3
water shade blooms
<dbl> <dbl> <dbl>
1 1 1 0
2 1 2 0
3 1 3 111.
4 2 1 183.
5 2 2 59.2
6 2 3 76.8
7 3 1 225.
8 3 2 83.8
9 3 3 135.
10 1 1 80.1
# ℹ 17 more rowsIn this data set the watering regime (water) and shading regime (shade) are encoded with numerical values. However, these numbers are actually categories, representing the amount of water/shade.
As such, we don’t want to treat these as numbers but as factors. At the moment they are numbers, which we can tell with <dbl>, which stands for double.
We can convert the columns using the as_factor() function. Because we’d like to keep referring to these columns as factors, we will update our existing data set.
# convert watering and shade regimes to factor
tulip <- tulip %>%
mutate(water = as_factor(water),
shade = as_factor(shade))This data set has three variables; blooms (which is the response variable) and water and shade (which are the two potential predictor variables).
Visualise the data
As always we’ll visualise the data first:
# by watering regime
ggplot(tulip,
aes(x = water, y = blooms)) +
geom_boxplot()
# by shading regime
ggplot(tulip,
aes(x = shade, y = blooms)) +
geom_boxplot()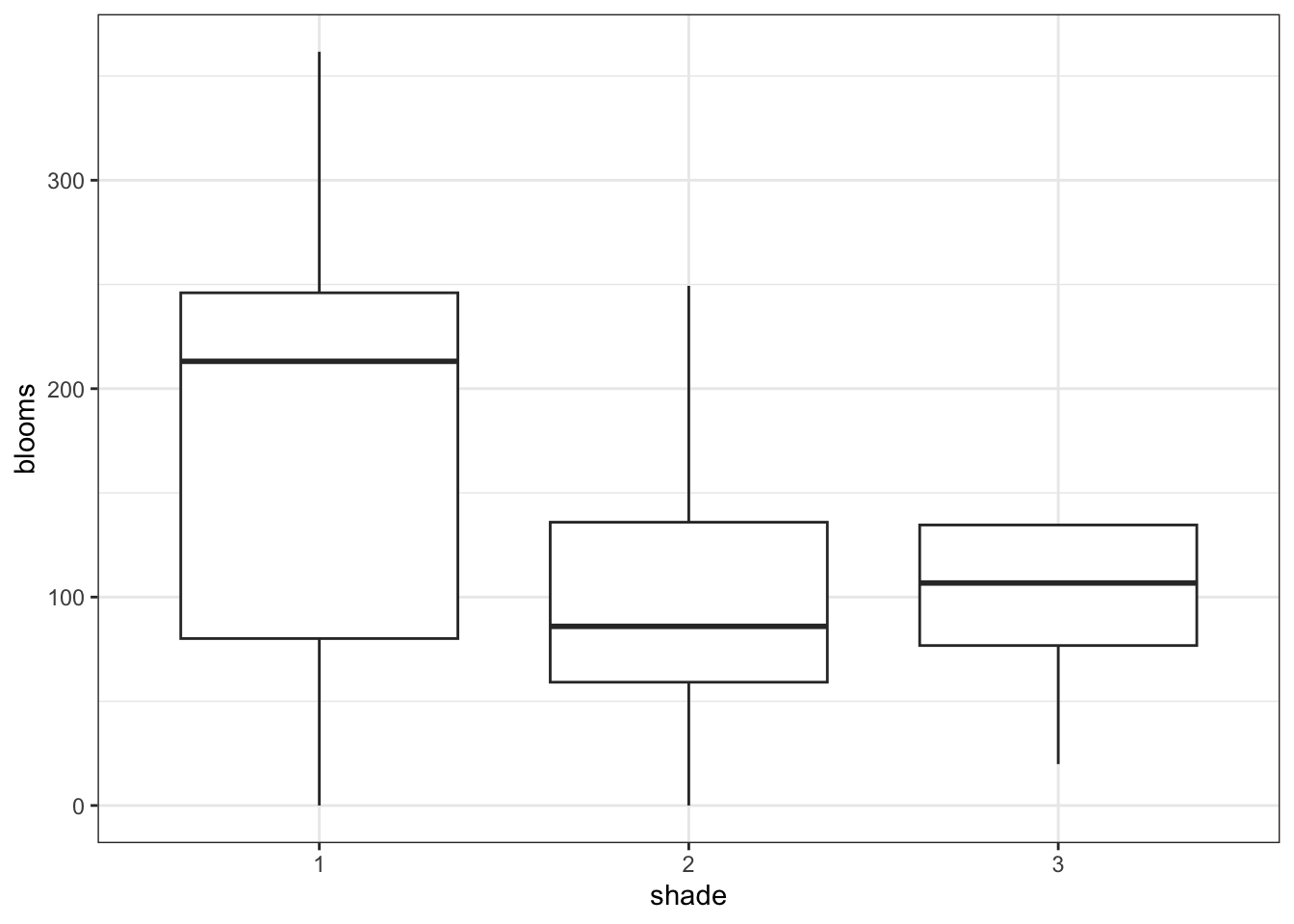
# interaction plot by watering regime
ggplot(tulip,
aes(x = shade,
y = blooms,
colour = water, group = water)) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(palette = "Dark2")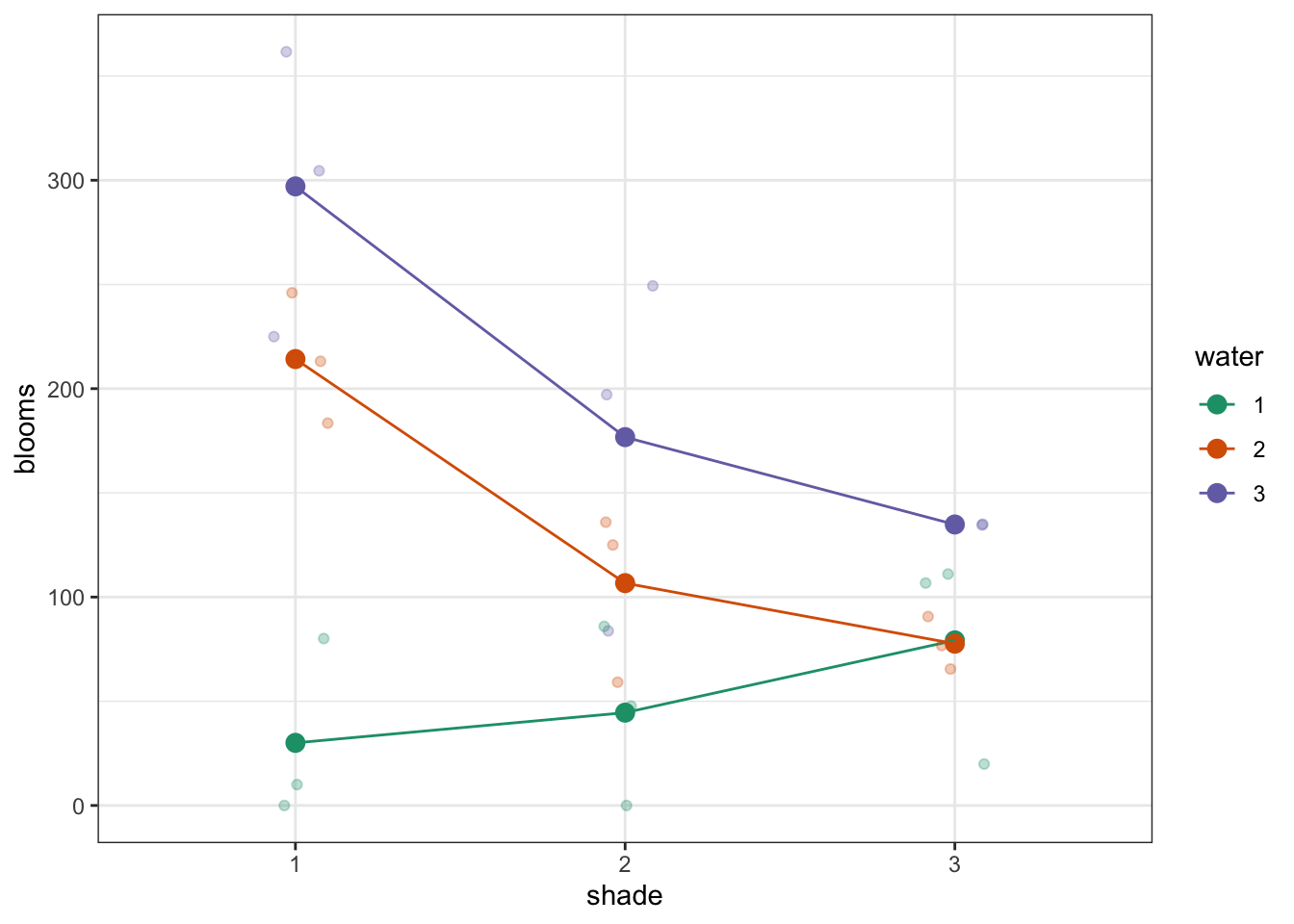
# interaction plot by shade regime
ggplot(tulip,
aes(x = water,
y = blooms,
colour = shade, group = shade)) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(palette = "Dark2")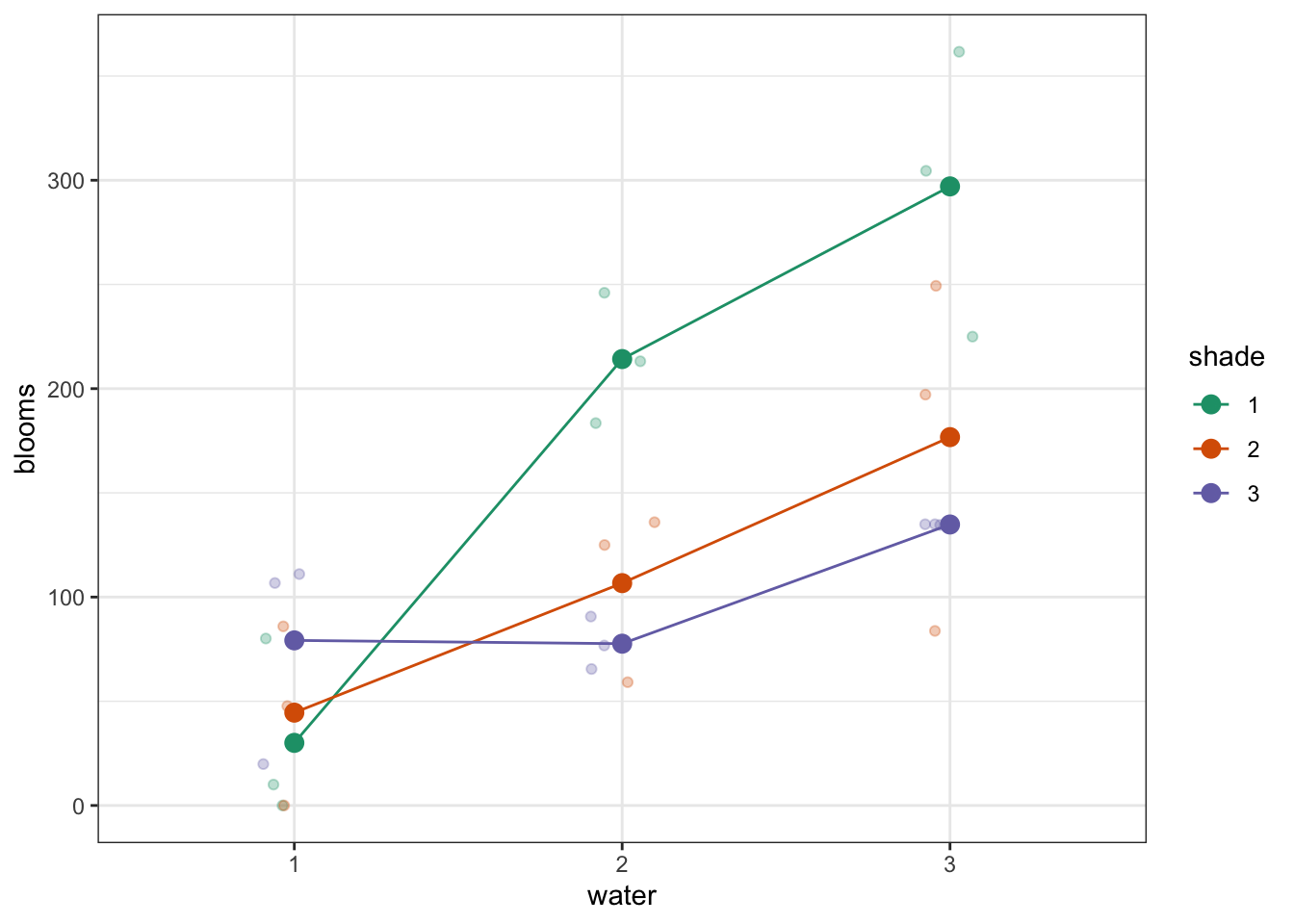
Again, both interaction plots suggest that there might be an interaction here. Digging in a little deeper from a descriptive perspective, it looks as though that water regime 1 is behaving differently to water regimes 2 and 3 under different shade conditions.
Assumptions
First we need to define the model:
# define the linear model
lm_tulip <- lm(blooms ~ water * shade,
data = tulip)Next, we check the assumptions:
resid_panel(lm_tulip,
plots = c("resid", "qq", "ls", "cookd"),
smoother = TRUE)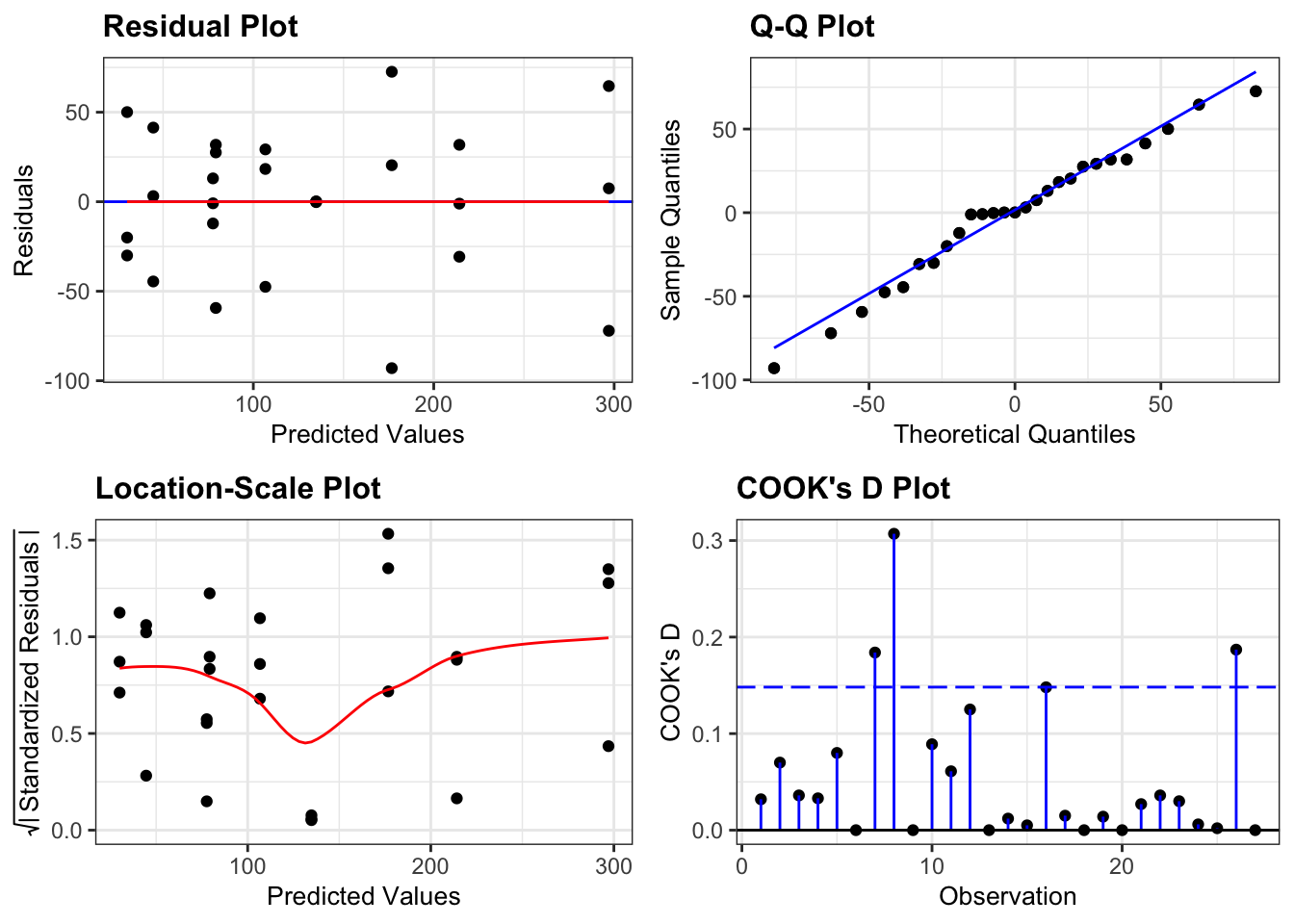
These are actually all OK. A two-way ANOVA analysis is on the cards.
Implement the test
Let’s carry out the two-way ANOVA.
# perform the ANOVA
anova(lm_tulip)Analysis of Variance Table
Response: blooms
Df Sum Sq Mean Sq F value Pr(>F)
water 2 103626 51813 22.0542 1.442e-05 ***
shade 2 36376 18188 7.7417 0.00375 **
water:shade 4 41058 10265 4.3691 0.01211 *
Residuals 18 42288 2349
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interpret the output and report results
So we do appear to have a significant interaction between water and shade as expected.
Load the data
# read in the data
tulip_py = pd.read_csv("data/CS4-tulip.csv")
# have a quick look at the data
tulip_py.head() water shade blooms
0 1 1 0.00
1 1 2 0.00
2 1 3 111.04
3 2 1 183.47
4 2 2 59.16In this data set the watering regime (water) and shading regime (shade) are encoded with numerical values. However, these numbers are actually categories, representing the amount of water/shade.
As such, we don’t want to treat these as numbers but as factors. We can convert the columns using astype(object). Because we’d like to keep referring to these columns as factors, we will update our existing data set.
# convert watering and shade regimes to factor
tulip_py['water'] = tulip_py['water'].astype(object)
tulip_py['shade'] = tulip_py['shade'].astype(object)This data set has three variables; blooms (which is the response variable) and water and shade (which are the two potential predictor variables).
Visualise the data
As always we’ll visualise the data first:
# by watering regime
(ggplot(tulip_py,
aes(x = "water", y = "blooms")) +
geom_boxplot())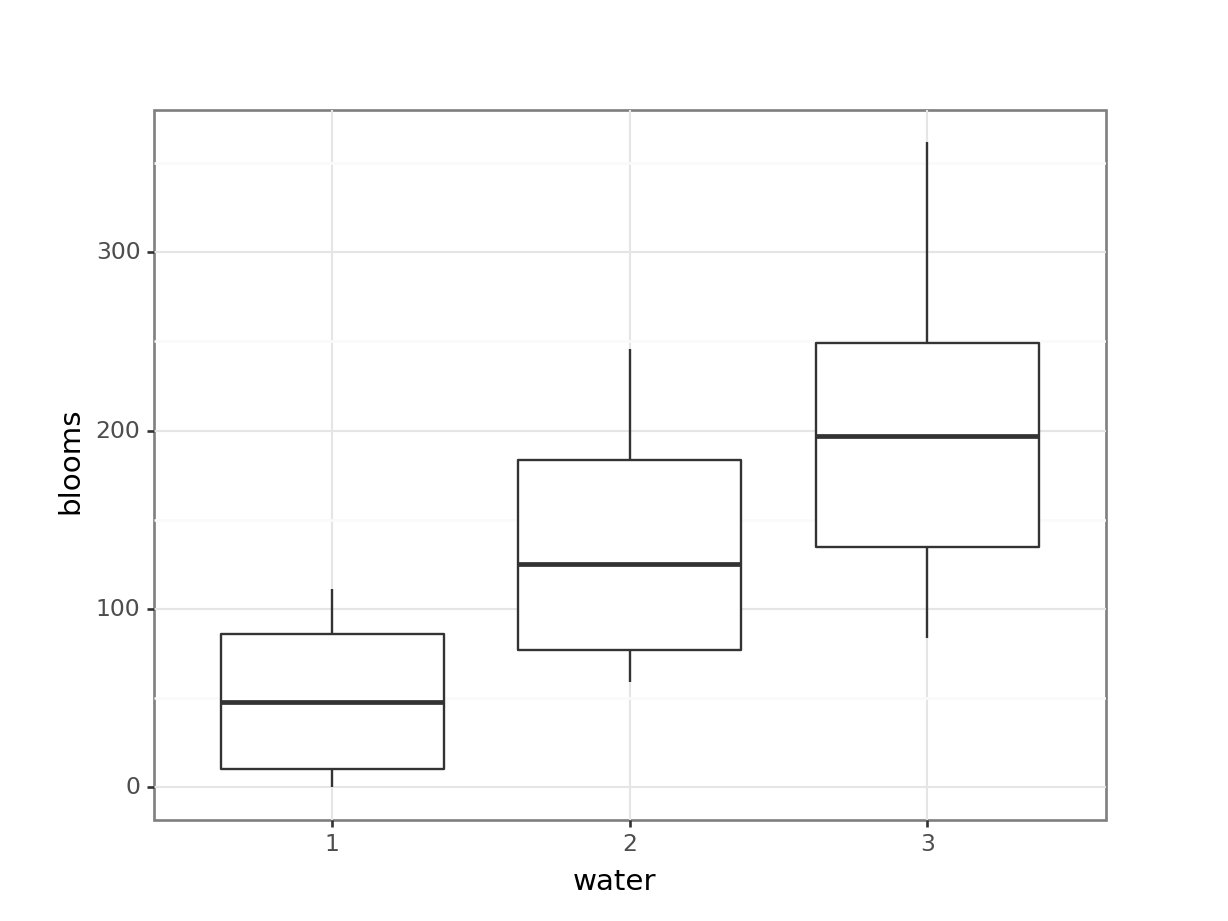
# by shading regime
(ggplot(tulip_py,
aes(x = "shade", y = "blooms")) +
geom_boxplot())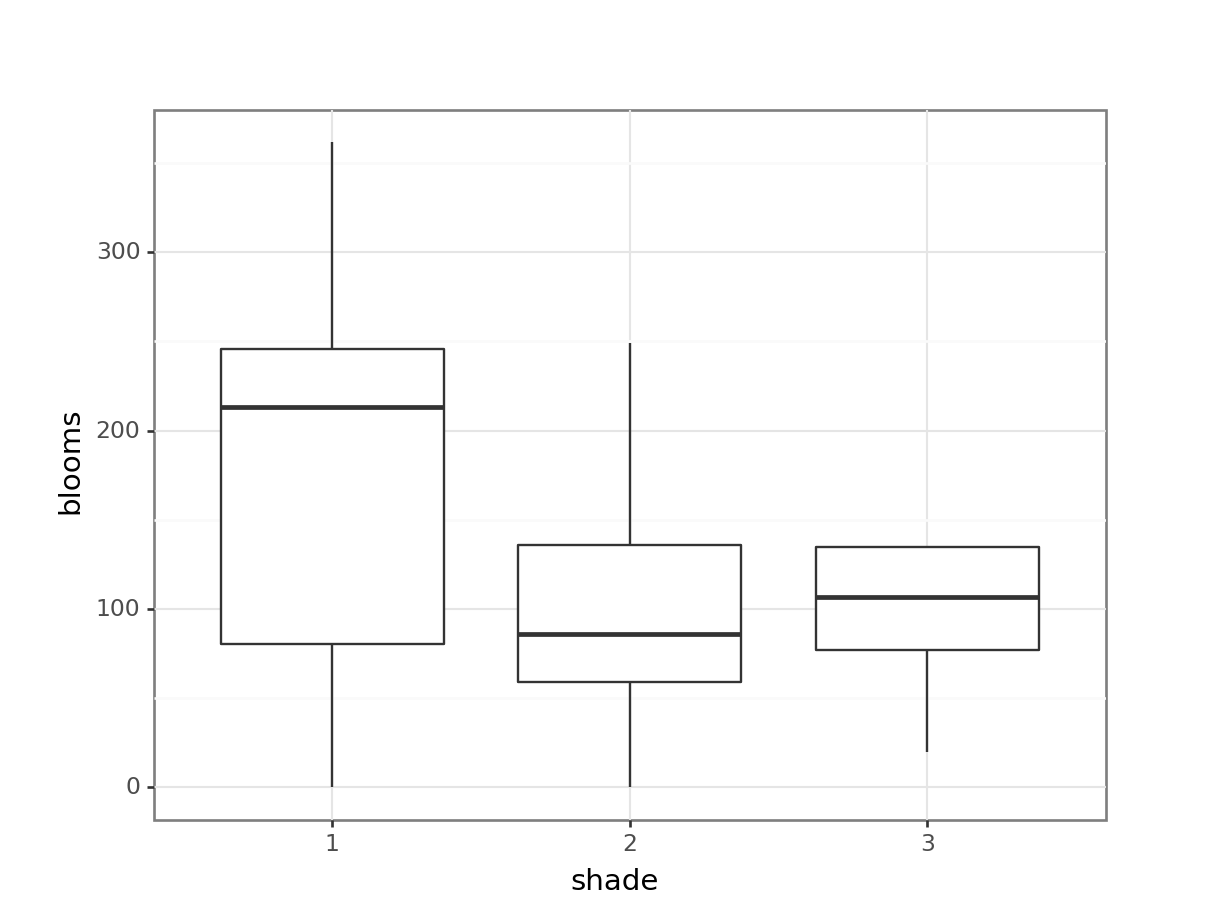
# interaction plot by watering regime
(ggplot(tulip_py,
aes(x = "shade", y = "blooms",
colour = "water", group = "water")) +
stat_summary(fun_data = "mean_cl_boot",
geom = "point", size = 3) +
stat_summary(fun_data = "mean_cl_boot",
geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(type = "qual", palette = "Dark2"))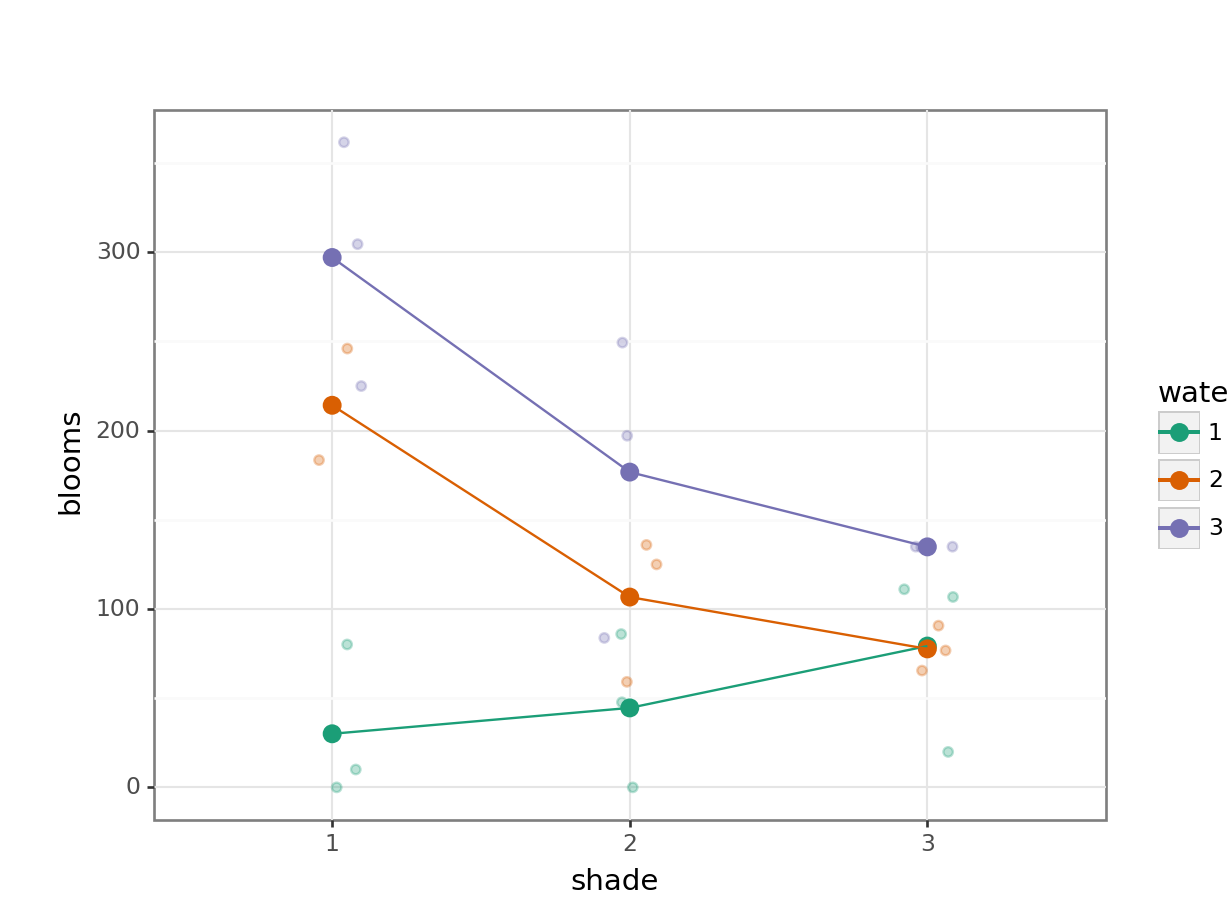
# interaction plot by shade regime
(ggplot(tulip_py,
aes(x = "water", y = "blooms",
colour = "shade", group = "shade")) +
stat_summary(fun_data = "mean_cl_boot",
geom = "point", size = 3) +
stat_summary(fun_data = "mean_cl_boot",
geom = "line") +
geom_jitter(alpha = 0.3, width = 0.1) +
scale_colour_brewer(type = "qual", palette = "Dark2"))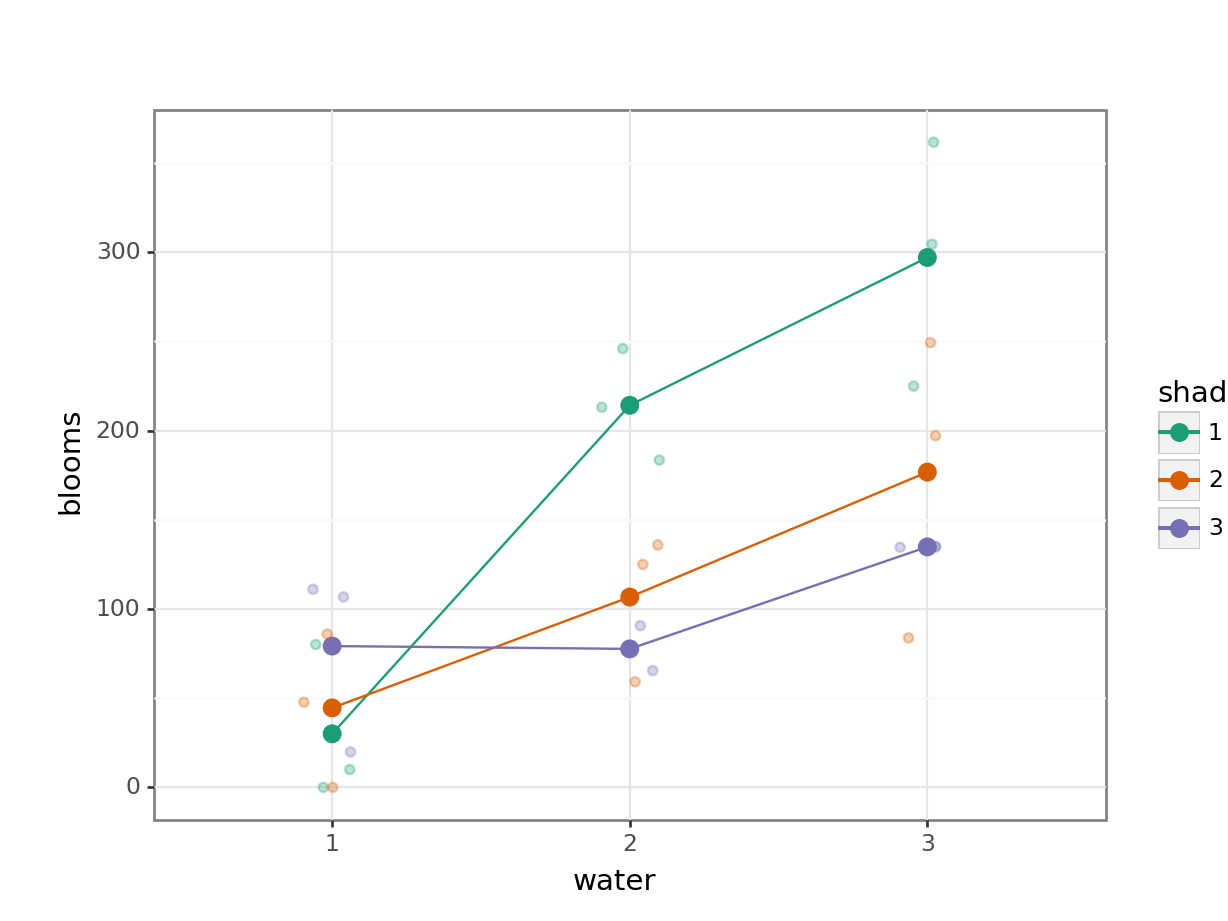
Again, both interaction plots suggest that there might be an interaction here. Digging in a little deeper from a descriptive perspective, it looks as though that water regime 1 is behaving differently to water regimes 2 and 3 under different shade conditions.
Assumptions
First we need to define the model:
# create a linear model
model = smf.ols(formula= "blooms ~ water * shade", data = tulip_py)
# and get the fitted parameters of the model
lm_tulip_py = model.fit()Next, we check the assumptions:
dgplots(lm_tulip_py)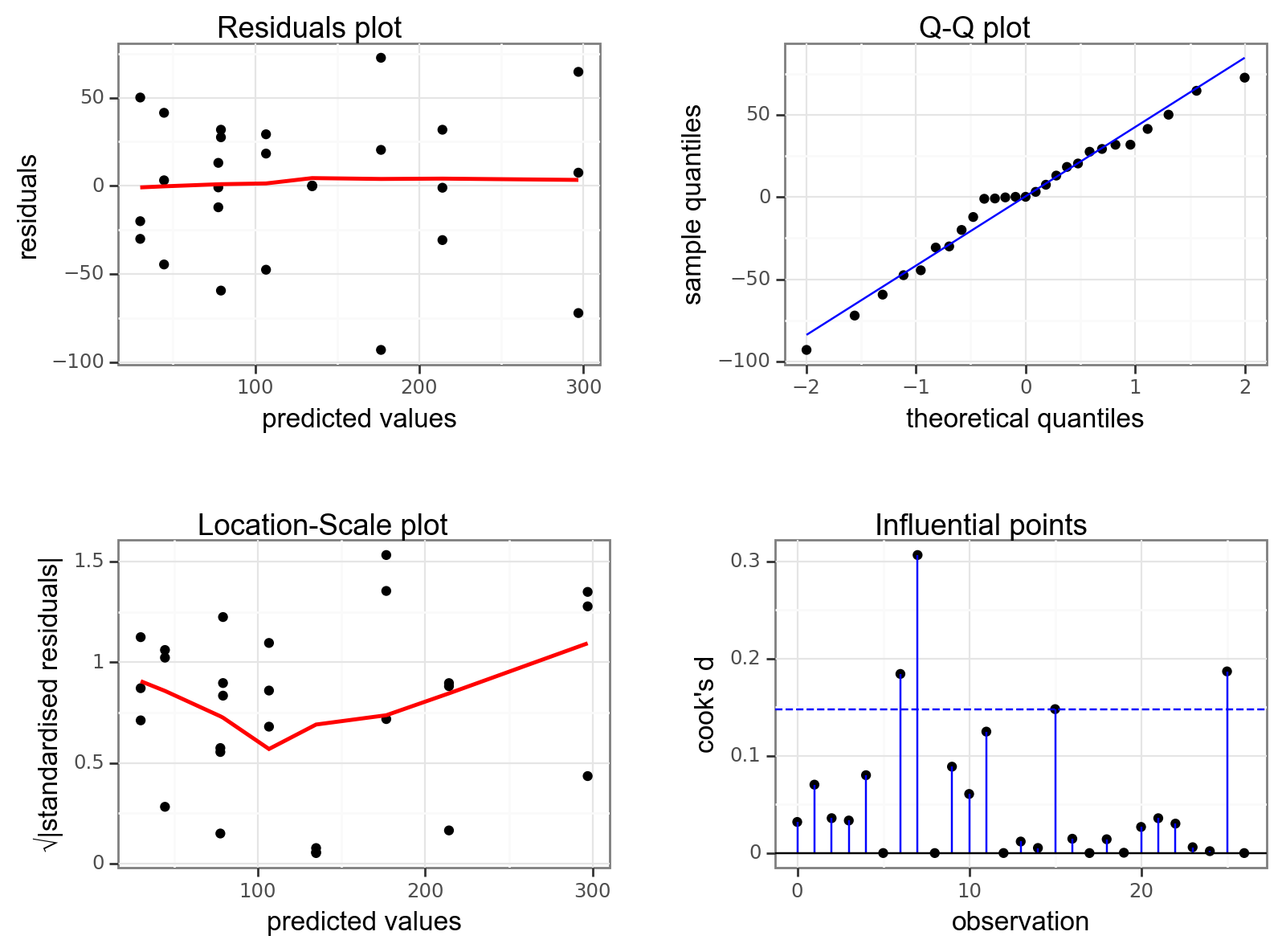
These are actually all OK. A two-way ANOVA analysis is on the cards.
Implement the test
Let’s carry out the two-way ANOVA.
sm.stats.anova_lm(lm_tulip_py, typ = 2) sum_sq df F PR(>F)
water 103625.786985 2.0 22.054200 0.000014
shade 36375.936807 2.0 7.741723 0.003750
water:shade 41058.139437 4.0 4.369108 0.012108
Residual 42288.185200 18.0 NaN NaNInterpret the output and report results
So we do appear to have a significant interaction between water and shade as expected.
A two-way ANOVA showed that there is a significant interaction between watering and shading regimes on number of blooms (p = 1.21e-02).
14.9 Summary
Key points
- A two-way ANOVA is used when there are two categorical variables and a single continuous variable
- We can visually check for interactions between the categorical variables by using interaction plots
- The two-way ANOVA is a type of linear model and assumes the following:
- the data have no systematic pattern
- the residuals are normally distributed
- the residuals have homogeneity of variance
- the fit does not depend on a single point (no single point has high leverage)