# A maths library
import math
# A Python data analysis and manipulation tool
import pandas as pd
# Python equivalent of `ggplot2`
from plotnine import *
# Statistical models, conducting tests and statistical data exploration
import statsmodels.api as sm
# Convenience interface for specifying models using formula strings and DataFrames
import statsmodels.formula.api as smf11 Binary response
Learning outcomes
Questions
- How do we analyse data with a binary outcome?
- Can we test if our model is any good?
- Be able to perform a logistic regression with a binary outcome
- Predict outcomes of new data, based on a defined model
Objectives
- Be able to analyse binary outcome data
- Understand different methods of testing model fit
- Be able to make model predictions
11.1 Libraries and functions
Click to expand
11.1.1 Libraries
11.1.2 Functions
11.1.3 Libraries
11.1.4 Functions
The example in this section uses the following data set:
data/finches_early.csv
These data come from an analysis of gene flow across two finch species [@lamichhaney2020]. They are slightly adapted here for illustrative purposes.
The data focus on two species, Geospiza fortis and G. scandens. The original measurements are split by a uniquely timed event: a particularly strong El Niño event in 1983. This event changed the vegetation and food supply of the finches, allowing F1 hybrids of the two species to survive, whereas before 1983 they could not. The measurements are classed as early (pre-1983) and late (1983 onwards).
Here we are looking only at the early data. We are specifically focussing on the beak shape classification, which we saw earlier in Figure 5.5.
11.2 Load and visualise the data
First we load the data, then we visualise it.
early_finches <- read_csv("data/finches_early.csv")early_finches_py = pd.read_csv("data/finches_early.csv")Looking at the data, we can see that the pointed_beak column contains zeros and ones. These are actually yes/no classification outcomes and not numeric representations.
We’ll have to deal with this soon. For now, we can plot the data:
ggplot(early_finches,
aes(x = factor(pointed_beak),
y = blength)) +
geom_boxplot()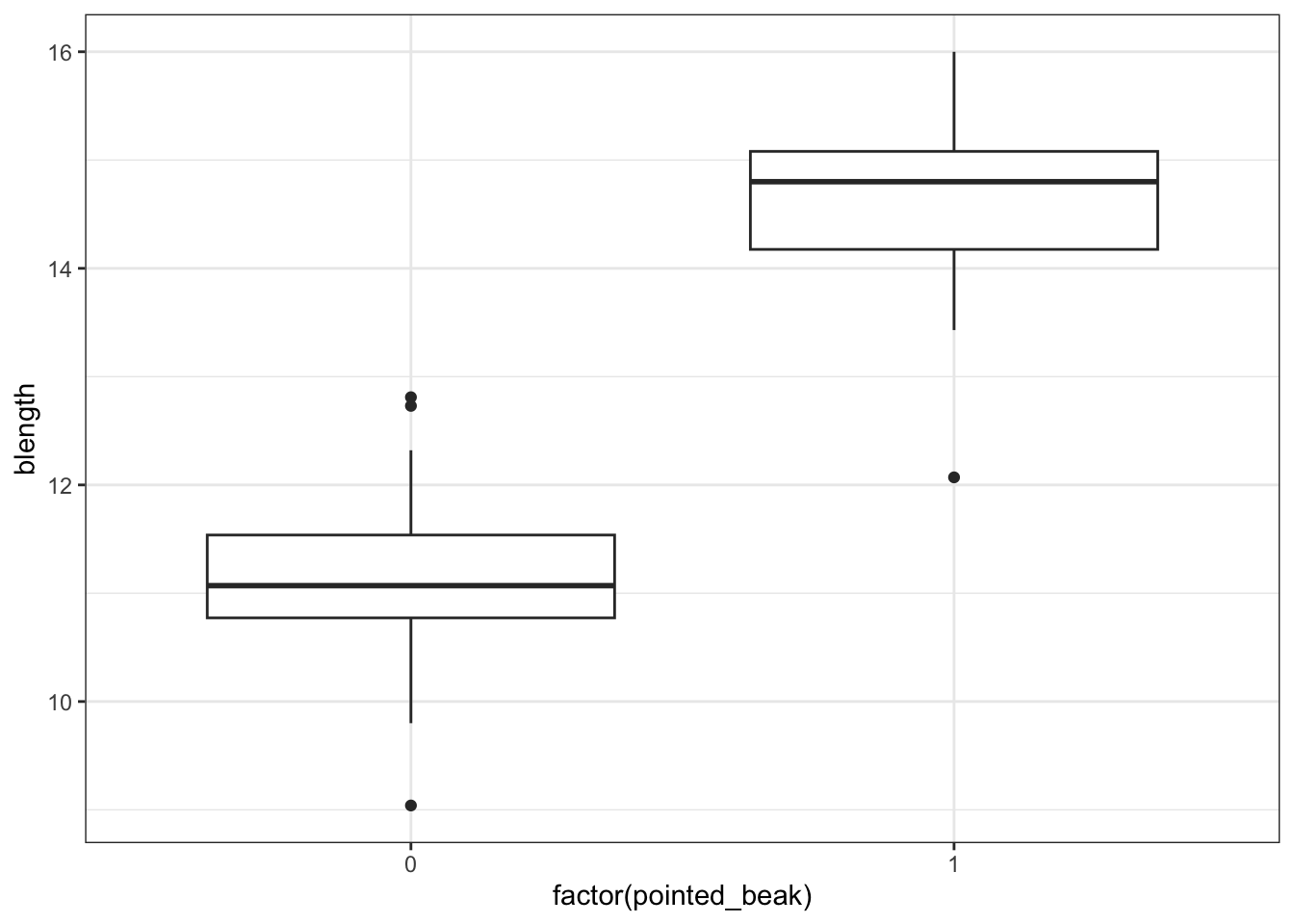
We could just give Python the pointed_beak data directly, but then it would view the values as numeric. Which doesn’t really work, because we have two groups as such: those with a pointed beak (1), and those with a blunt one (0).
We can force Python to temporarily covert the data to a factor, by making the pointed_beak column an object type. We can do this directly inside the ggplot() function.
(ggplot(early_finches_py,
aes(x = early_finches_py.pointed_beak.astype(object),
y = "blength")) +
geom_boxplot())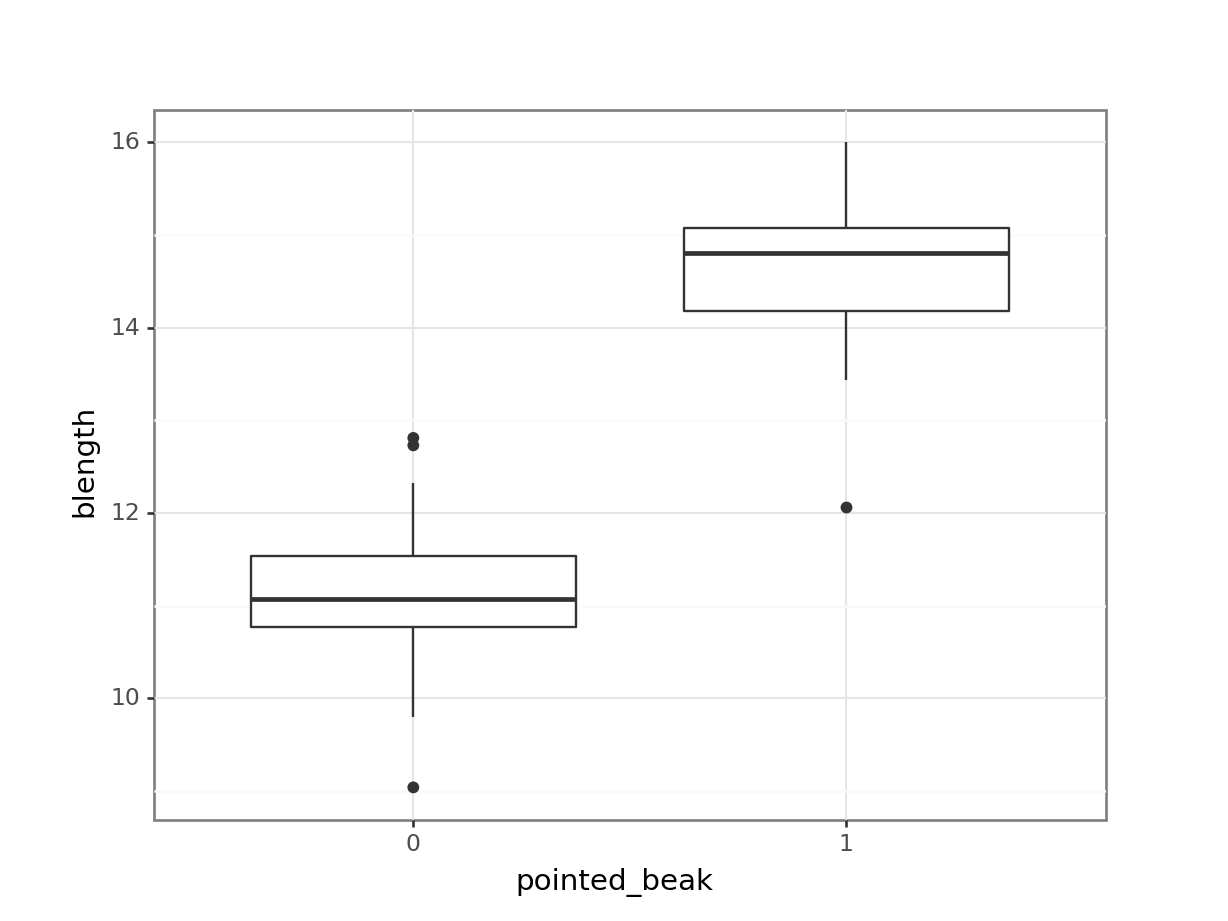
It looks as though the finches with blunt beaks generally have shorter beak lengths.
We can visualise that differently by plotting all the data points as a classic binary response plot:
ggplot(early_finches,
aes(x = blength, y = pointed_beak)) +
geom_point()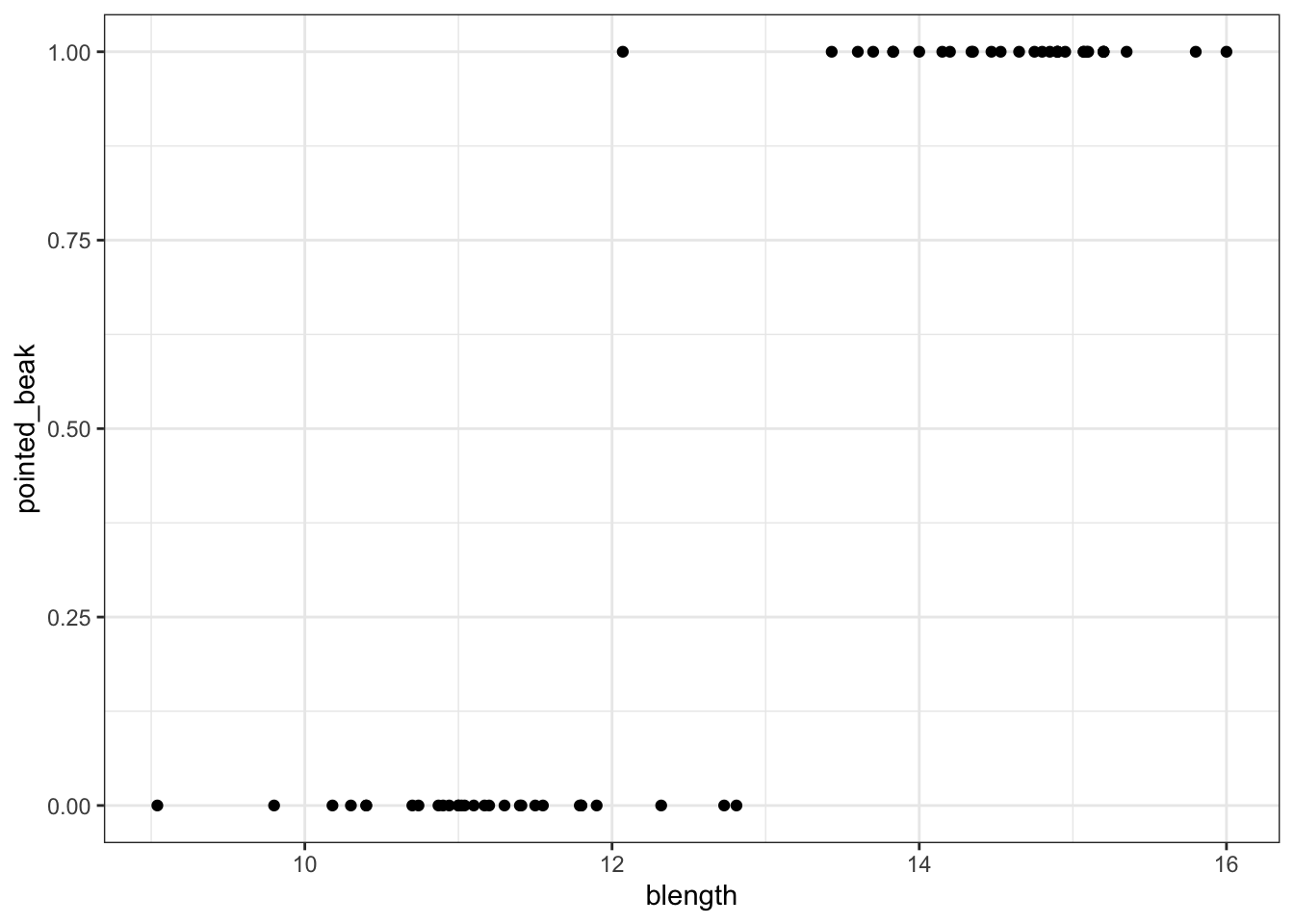
(ggplot(early_finches_py,
aes(x = "blength",
y = "pointed_beak")) +
geom_point())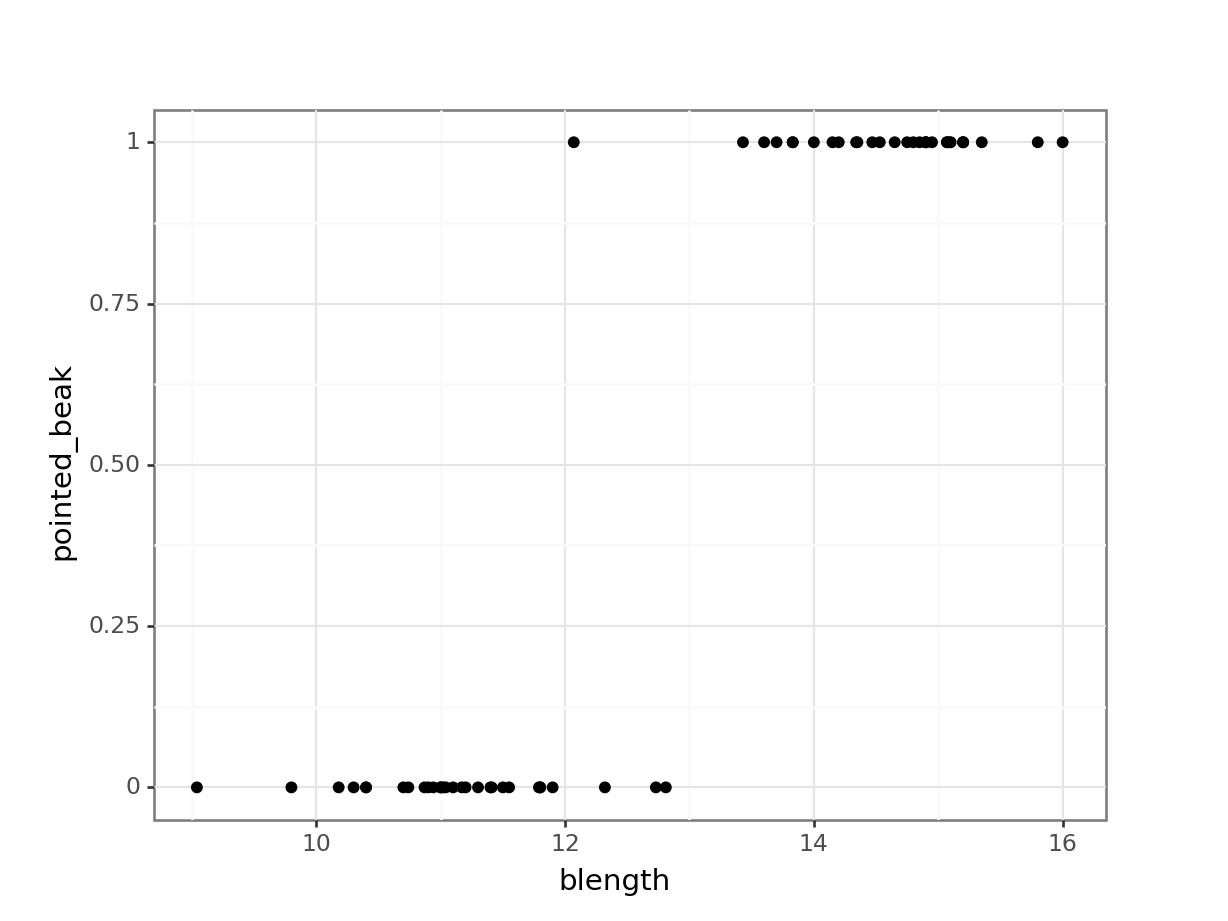
This presents us with a bit of an issue. We could fit a linear regression model to these data, although we already know that this is a bad idea…
ggplot(early_finches,
aes(x = blength, y = pointed_beak)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)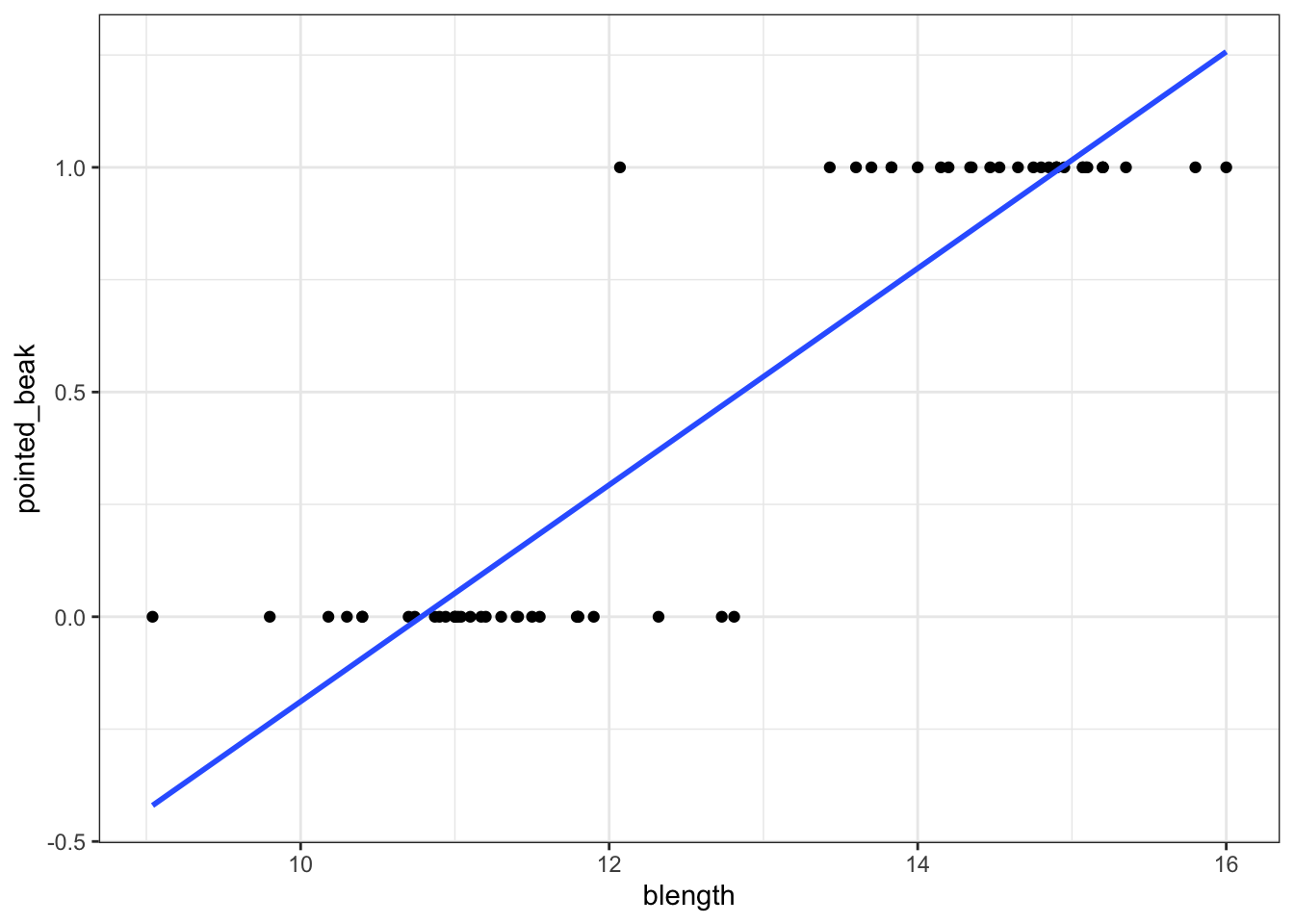
(ggplot(early_finches_py,
aes(x = "blength",
y = "pointed_beak")) +
geom_point() +
geom_smooth(method = "lm",
colour = "blue",
se = False))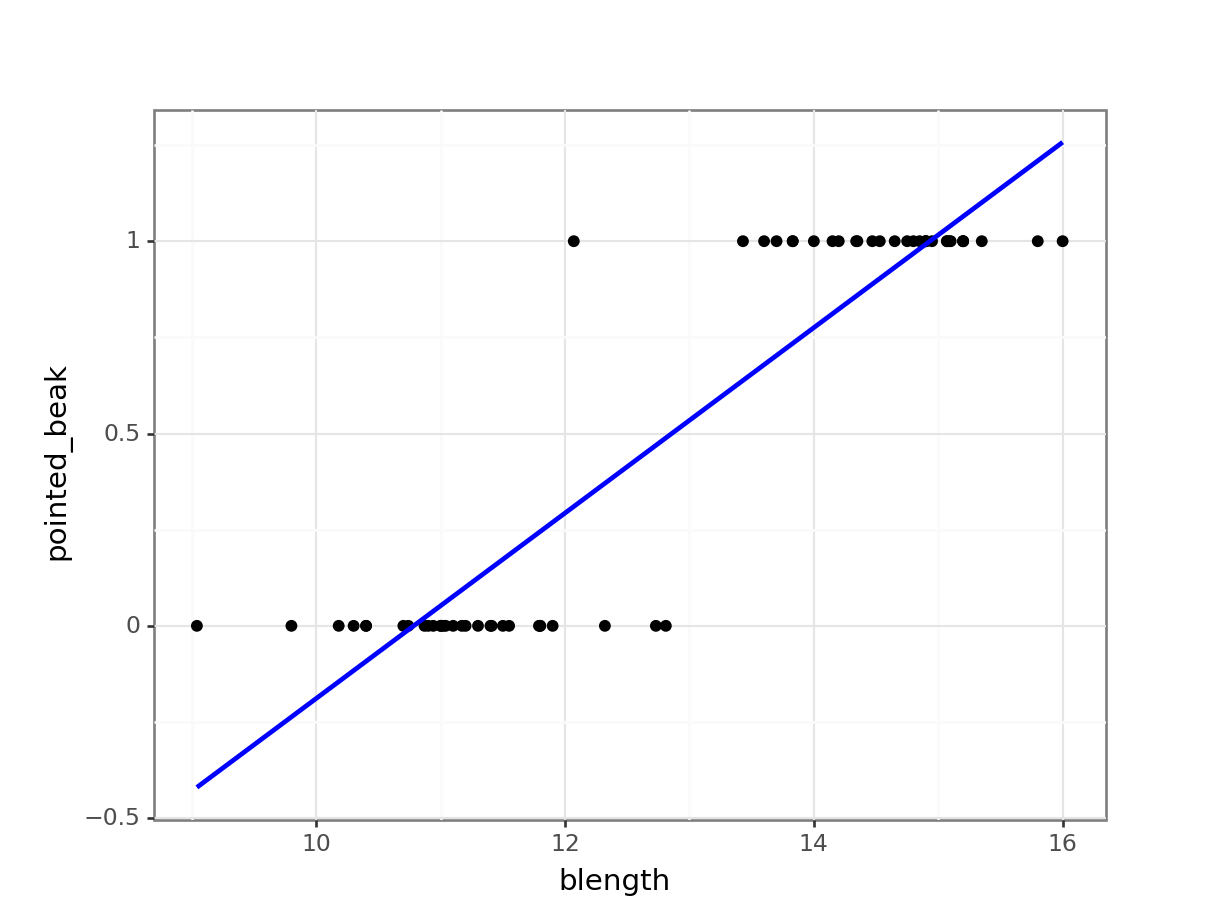
Of course this is rubbish - we can’t have a beak classification outside the range of \([0, 1]\). It’s either blunt (0) or pointed (1).
But for the sake of exploration, let’s look at the assumptions:
lm_bks <- lm(pointed_beak ~ blength,
data = early_finches)
resid_panel(lm_bks,
plots = c("resid", "qq", "ls", "cookd"),
smoother = TRUE)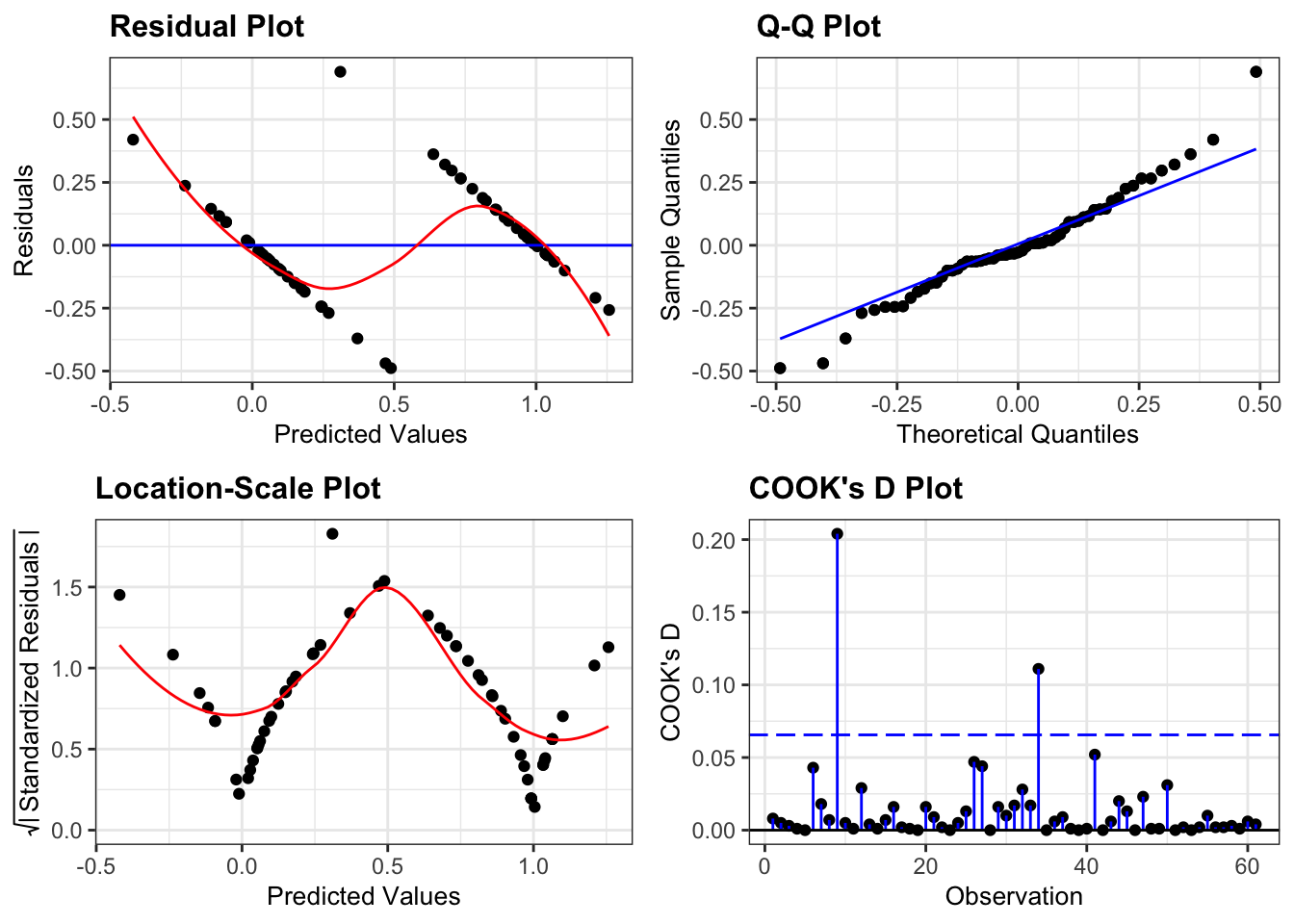
First, we create a linear model:
# create a linear model
model = smf.ols(formula = "pointed_beak ~ blength",
data = early_finches_py)
# and get the fitted parameters of the model
lm_bks_py = model.fit()Next, we can create the diagnostic plots:
dgplots(lm_bks_py)
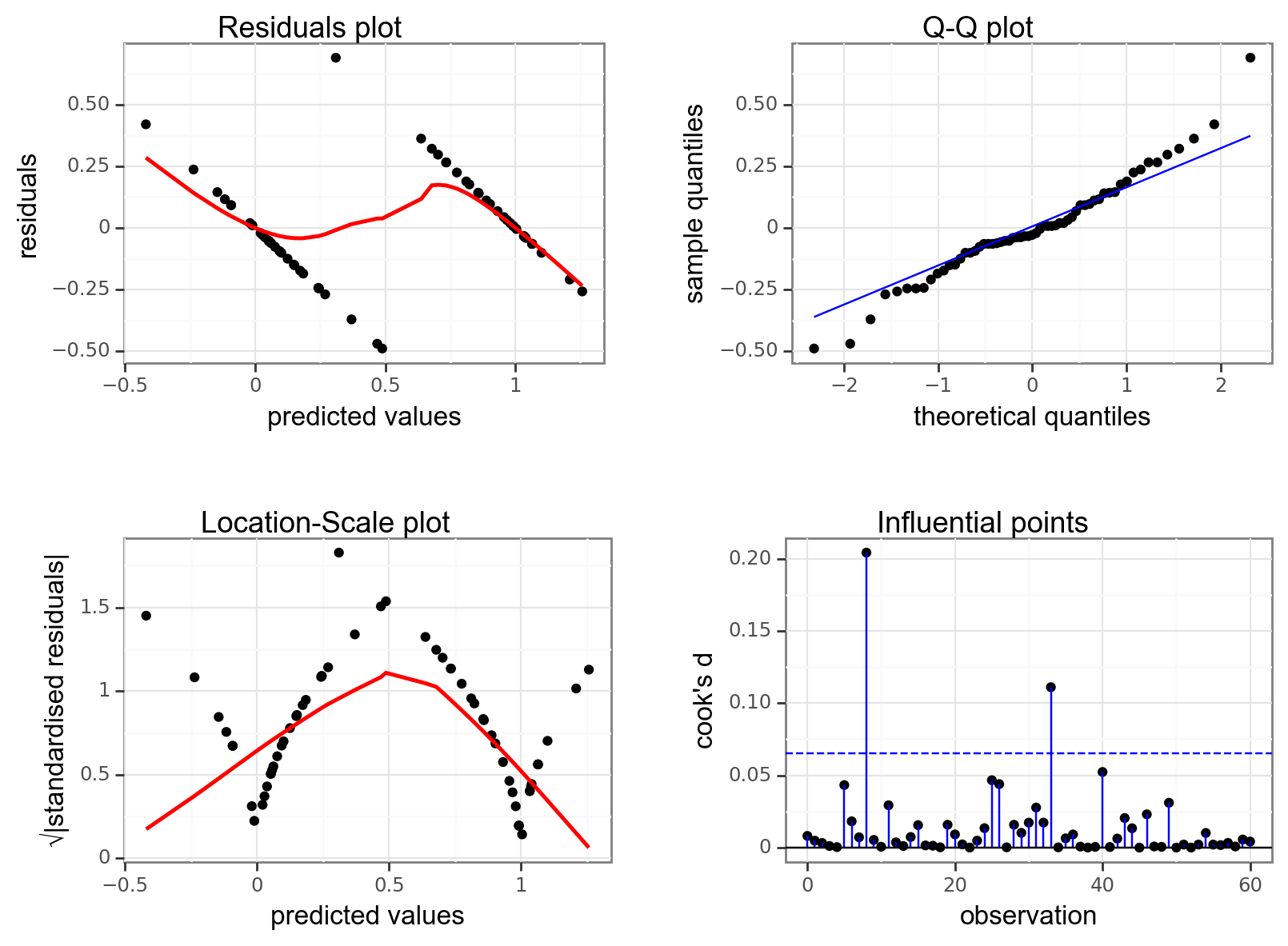
They’re pretty extremely bad.
- The response is not linear (Residual Plot, binary response plot, common sense).
- The residuals do not appear to be distributed normally (Q-Q Plot)
- The variance is not homogeneous across the predicted values (Location-Scale Plot)
- But - there is always a silver lining - we don’t have influential data points.
11.3 Creating a suitable model
So far we’ve established that using a simple linear model to describe a potential relationship between beak length and the probability of having a pointed beak is not a good idea. So, what can we do?
One of the ways we can deal with binary outcome data is by performing a logistic regression. Instead of fitting a straight line to our data, and performing a regression on that, we fit a line that has an S shape. This avoids the model making predictions outside the \([0, 1]\) range.
We described our standard linear relationship as follows:
\(Y = \beta_0 + \beta_1X\)
We can now map this to our non-linear relationship via the logistic link function:
\(Y = \frac{\exp(\beta_0 + \beta_1X)}{1 + \exp(\beta_0 + \beta_1X)}\)
Note that the \(\beta_0 + \beta_1X\) part is identical to the formula of a straight line.
The rest of the function is what makes the straight line curve into its characteristic S shape.
Euler’s number (\(\exp\)): would you like to know more?
In mathematics, \(\rm e\) represents a constant of around 2.718. Another notation is \(\exp\), which is often used when notations become a bit cumbersome. Here, I exclusively use the \(\exp\) notation for consistency.
We can fit such an S-shaped curve to our early_finches data set, by creating a generalised linear model.
In R we have a few options to do this, and by far the most familiar function would be glm(). Here we save the model in an object called glm_bks:
glm_bks <- glm(pointed_beak ~ blength,
family = binomial,
data = early_finches)The format of this function is similar to that used by the lm() function for linear models. The important difference is that we must specify the family of error distribution to use. For logistic regression we must set the family to binomial.
If you forget to set the family argument, then the glm() function will perform a standard linear model fit, identical to what the lm() function would do.
# create a linear model
model = smf.glm(formula = "pointed_beak ~ blength",
family = sm.families.Binomial(),
data = early_finches_py)
# and get the fitted parameters of the model
glm_bks_py = model.fit()11.4 Model output
That’s the easy part done! The trickier part is interpreting the output. First of all, we’ll get some summary information.
summary(glm_bks)
Call:
glm(formula = pointed_beak ~ blength, family = binomial, data = early_finches)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -43.410 15.250 -2.847 0.00442 **
blength 3.387 1.193 2.839 0.00452 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 84.5476 on 60 degrees of freedom
Residual deviance: 9.1879 on 59 degrees of freedom
AIC: 13.188
Number of Fisher Scoring iterations: 8print(glm_bks_py.summary()) Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: pointed_beak No. Observations: 61
Model: GLM Df Residuals: 59
Model Family: Binomial Df Model: 1
Link Function: Logit Scale: 1.0000
Method: IRLS Log-Likelihood: -4.5939
Date: Thu, 25 Jan 2024 Deviance: 9.1879
Time: 08:38:26 Pearson chi2: 15.1
No. Iterations: 8 Pseudo R-squ. (CS): 0.7093
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -43.4096 15.250 -2.847 0.004 -73.298 -13.521
blength 3.3866 1.193 2.839 0.005 1.049 5.724
==============================================================================There’s a lot to unpack here, but for the purpose of today we are mostly focussing on the coefficients.
The coefficients can be found in the Coefficients block. The main numbers to extract from the output are the two numbers underneath Estimate.Std:
Coefficients:
Estimate Std.
(Intercept) -43.410
blength 3.387 Right at the bottom is a table showing the model coefficients. The main numbers to extract from the output are the two numbers in the coef column:
======================
coef
----------------------
Intercept -43.4096
blength 3.3866
======================These are the coefficients of the logistic model equation and need to be placed in the correct equation if we want to be able to calculate the probability of having a pointed beak for a given beak length.
The \(p\) values at the end of each coefficient row merely show whether that particular coefficient is significantly different from zero. This is similar to the \(p\) values obtained in the summary output of a linear model. As with continuous predictors in simple models, these \(p\) values can be used to decide whether that predictor is important (so in this case beak length appears to be significant). However, these \(p\) values aren’t great to work with when we have multiple predictor variables, or when we have categorical predictors with multiple levels (since the output will give us a \(p\) value for each level rather than for the predictor as a whole).
We can use the coefficients to calculate the probability of having a pointed beak for a given beak length:
\[ P(pointed \ beak) = \frac{\exp(-43.41 + 3.39 \times blength)}{1 + \exp(-43.41 + 3.39 \times blength)} \]
Having this formula means that we can calculate the probability of having a pointed beak for any beak length. How do we work this out in practice?
Well, the probability of having a pointed beak if the beak length is large (for example 15 mm) can be calculated as follows:
exp(-43.41 + 3.39 * 15) / (1 + exp(-43.41 + 3.39 * 15))[1] 0.9994131If the beak length is small (for example 10 mm), the probability of having a pointed beak is extremely low:
exp(-43.41 + 3.39 * 10) / (1 + exp(-43.41 + 3.39 * 10))[1] 7.410155e-05Well, the probability of having a pointed beak if the beak length is large (for example 15 mm) can be calculated as follows:
# import the math library
import mathmath.exp(-43.41 + 3.39 * 15) / (1 + math.exp(-43.41 + 3.39 * 15))0.9994130595039192If the beak length is small (for example 10 mm), the probability of having a pointed beak is extremely low:
math.exp(-43.41 + 3.39 * 10) / (1 + math.exp(-43.41 + 3.39 * 10))7.410155028945912e-05We can calculate the the probabilities for all our observed values and if we do that then we can see that the larger the beak length is, the higher the probability that a beak shape would be pointed. I’m visualising this together with the logistic curve, where the blue points are the calculated probabilities:
Code available here
glm_bks %>%
augment(type.predict = "response") %>%
ggplot() +
geom_point(aes(x = blength, y = pointed_beak)) +
geom_line(aes(x = blength, y = .fitted),
linetype = "dashed",
colour = "blue") +
geom_point(aes(x = blength, y = .fitted),
colour = "blue", alpha = 0.5) +
labs(x = "beak length (mm)",
y = "Probability")(ggplot(early_finches_py) +
geom_point(aes(x = "blength", y = "pointed_beak")) +
geom_line(aes(x = "blength", y = glm_bks_py.fittedvalues),
linetype = "dashed",
colour = "blue") +
geom_point(aes(x = "blength", y = glm_bks_py.fittedvalues),
colour = "blue", alpha = 0.5) +
labs(x = "beak length (mm)",
y = "Probability"))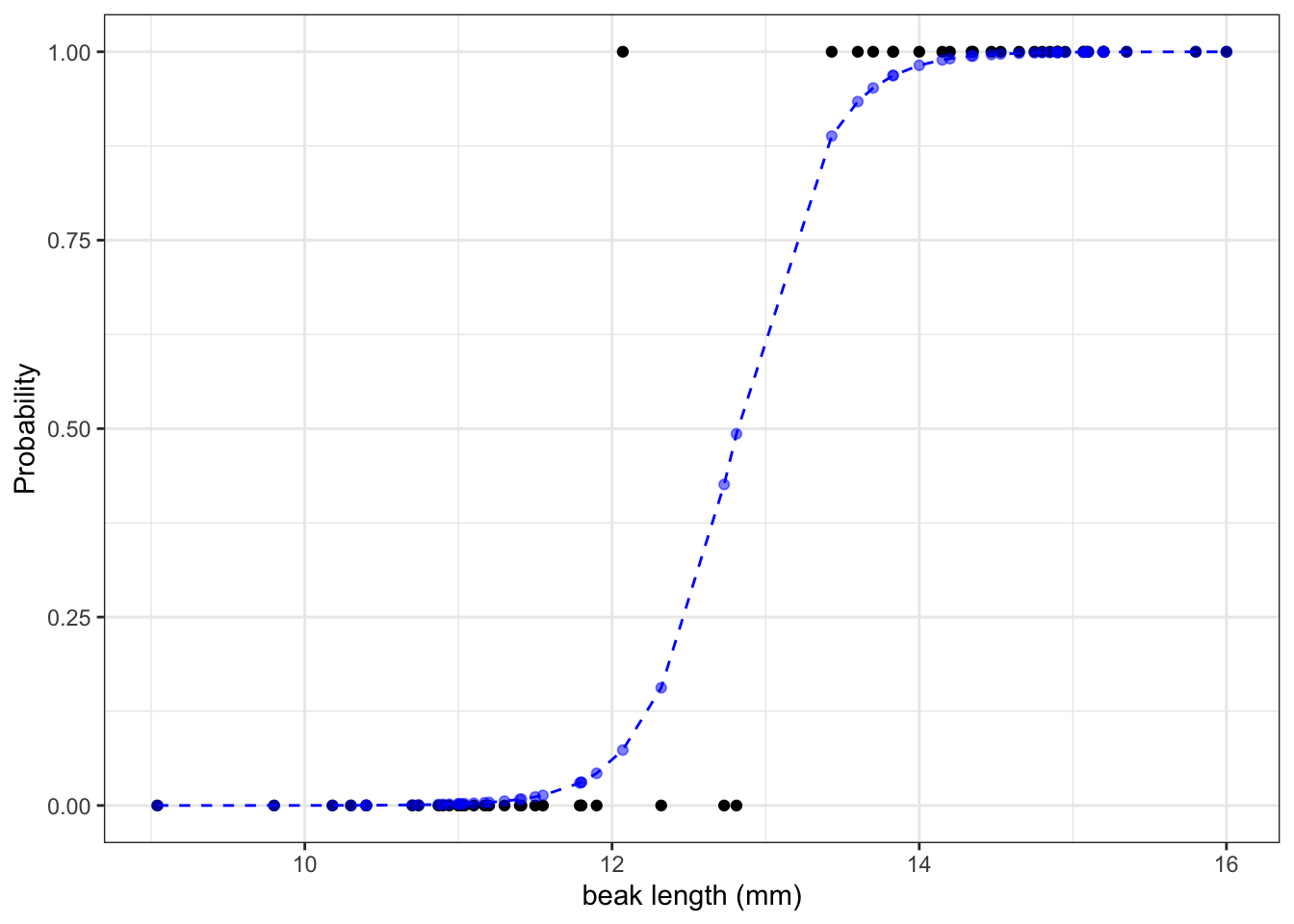
The graph shows us that, based on the data that we have and the model we used to make predictions about our response variable, the probability of seeing a pointed beak increases with beak length.
Short beaks are more closely associated with the bluntly shaped beaks, whereas long beaks are more closely associated with the pointed shape. It’s also clear that there is a range of beak lengths (around 13 mm) where the probability of getting one shape or another is much more even.
There is an interesting genetic story behind all this, but that will be explained in more detail in the full-day Generalised linear models course.
11.5 Exercises
11.5.1 Diabetes
Exercise
Level:
For this exercise we’ll be using the data from data/diabetes.csv.
This is a data set comprising 768 observations of three variables (one dependent and two predictor variables). This records the results of a diabetes test result as a binary variable (1 is a positive result, 0 is a negative result), along with the result of a glucose tolerance test and the diastolic blood pressure for each of 768 women. The variables are called test_result, glucose and diastolic.
We want to see if the glucose tolerance is a meaningful predictor for predictions on a diabetes test. To investigate this, do the following:
- Load and visualise the data
- Create a suitable model
- Determine if there are any statistically significant predictors
- Calculate the probability of a positive diabetes test result for a glucose tolerance test value of
glucose = 150
Answer
11.6 Answer
Load and visualise the data
First we load the data, then we visualise it.
diabetes <- read_csv("data/diabetes.csv")diabetes_py = pd.read_csv("data/diabetes.csv")Looking at the data, we can see that the test_result column contains zeros and ones. These are yes/no test result outcomes and not actually numeric representations.
We’ll have to deal with this soon. For now, we can plot the data, by outcome:
ggplot(diabetes,
aes(x = factor(test_result),
y = glucose)) +
geom_boxplot()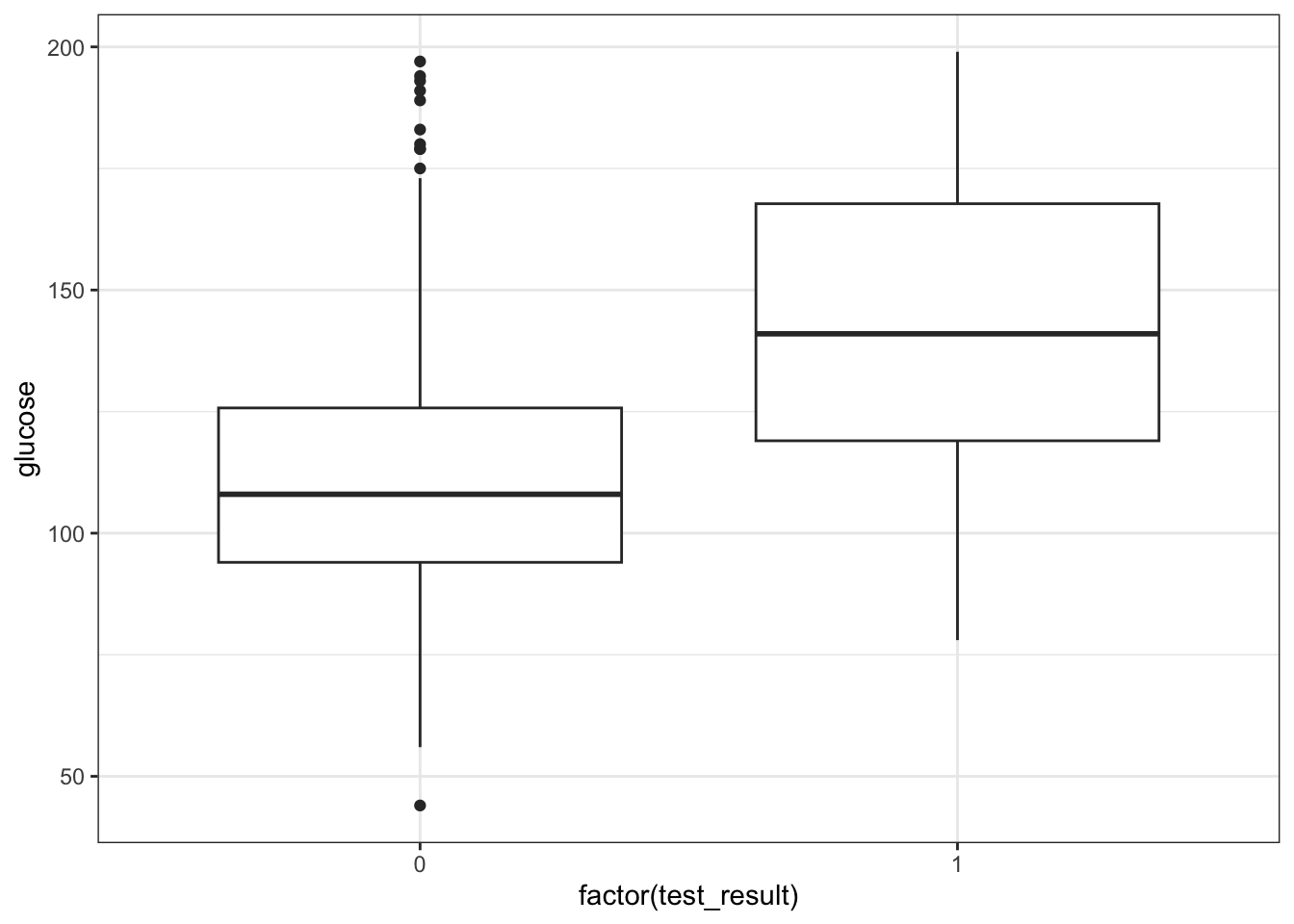
We could just give Python the test_result data directly, but then it would view the values as numeric. Which doesn’t really work, because we have two groups as such: those with a negative diabetes test result, and those with a positive one.
We can force Python to temporarily covert the data to a factor, by making the test_result column an object type. We can do this directly inside the ggplot() function.
(ggplot(diabetes_py,
aes(x = diabetes_py.test_result.astype(object),
y = "glucose")) +
geom_boxplot())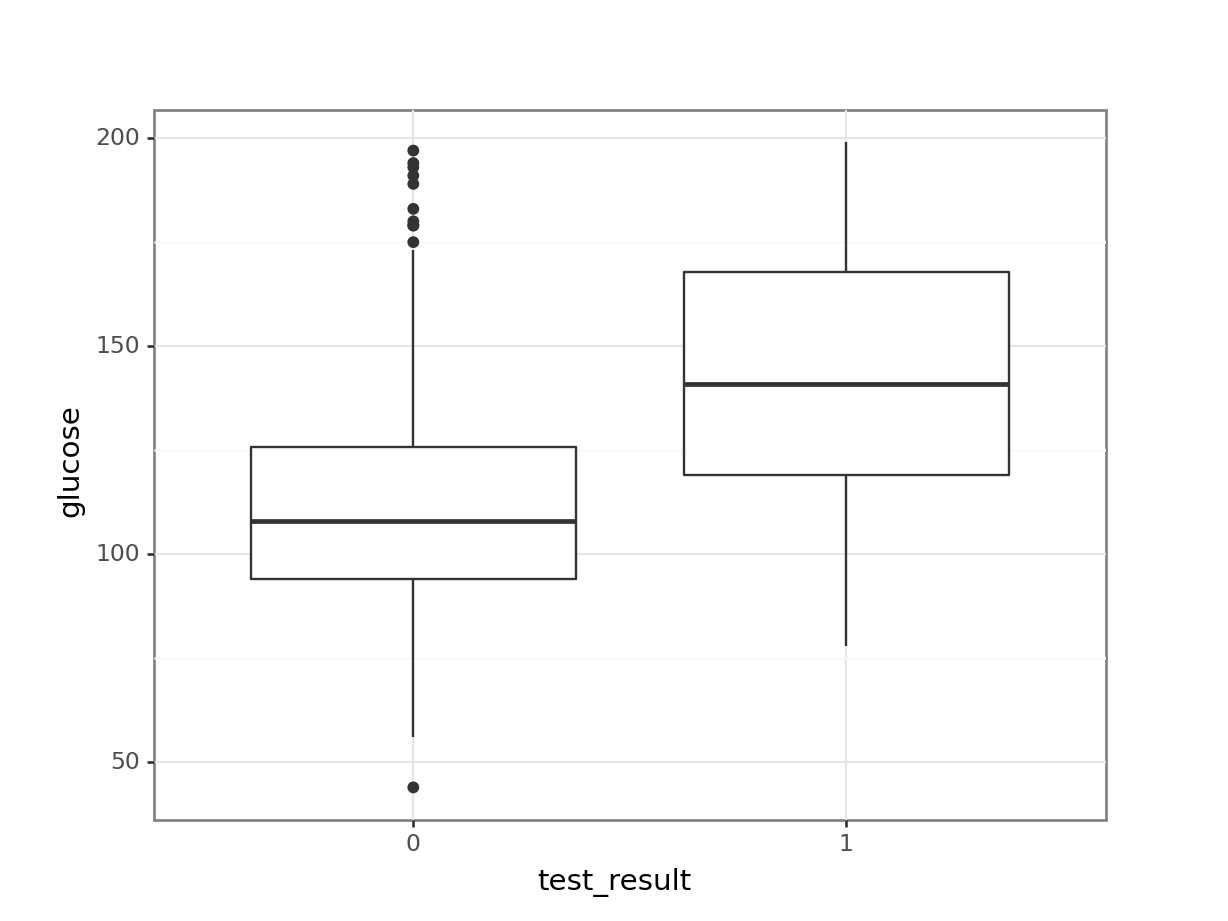
It looks as though the patients with a positive diabetes test have slightly higher glucose levels than those with a negative diabetes test.
We can visualise that differently by plotting all the data points as a classic binary response plot:
ggplot(diabetes,
aes(x = glucose,
y = test_result)) +
geom_point()
(ggplot(diabetes_py,
aes(x = "glucose",
y = "test_result")) +
geom_point())
Create a suitable model
We’ll use the glm() function to create a generalised linear model. Here we save the model in an object called glm_dia:
glm_dia <- glm(test_result ~ glucose,
family = binomial,
data = diabetes)The format of this function is similar to that used by the lm() function for linear models. The important difference is that we must specify the family of error distribution to use. For logistic regression we must set the family to binomial.
# create a linear model
model = smf.glm(formula = "test_result ~ glucose",
family = sm.families.Binomial(),
data = diabetes_py)
# and get the fitted parameters of the model
glm_dia_py = model.fit()Let’s look at the model parameters:
summary(glm_dia)
Call:
glm(formula = test_result ~ glucose, family = binomial, data = diabetes)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.611732 0.442289 -12.69 <2e-16 ***
glucose 0.039510 0.003398 11.63 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 936.6 on 727 degrees of freedom
Residual deviance: 752.2 on 726 degrees of freedom
AIC: 756.2
Number of Fisher Scoring iterations: 4print(glm_dia_py.summary()) Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: test_result No. Observations: 728
Model: GLM Df Residuals: 726
Model Family: Binomial Df Model: 1
Link Function: Logit Scale: 1.0000
Method: IRLS Log-Likelihood: -376.10
Date: Thu, 25 Jan 2024 Deviance: 752.20
Time: 08:38:30 Pearson chi2: 713.
No. Iterations: 4 Pseudo R-squ. (CS): 0.2238
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -5.6117 0.442 -12.688 0.000 -6.479 -4.745
glucose 0.0395 0.003 11.628 0.000 0.033 0.046
==============================================================================We can see that glucose is a significant predictor for the test_result (the \(p\) value is much smaller than 0.05).
Knowing this, we’re interested in the coefficients. We have an intercept of -5.61 and 0.0395 for glucose. We can use these coefficients to write a formula that describes the potential relationship between the probability of having a positive test result, dependent on the glucose tolerance level value:
\[ P(positive \ test\ result) = \frac{\exp(-5.61 + 0.04 \times glucose)}{1 + \exp(-5.61 + 0.04 \times glucose)} \]
Calculating probabilities
Using the formula above, we can now calculate the probability of having a positive test result, for a given glucose value. If we do this for glucose = 150, we get the following:
exp(-5.61 + 0.04 * 150) / (1 + exp(-5.61 + 0.04 * 145))[1] 0.6685441math.exp(-5.61 + 0.04 * 150) / (1 + math.exp(-5.61 + 0.04 * 145))0.6685441044999503This tells us that the probability of having a positive diabetes test result, given a glucose tolerance level of 150 is around 67%.
11.7 Summary
Key points
- We use a logistic regression to model a binary response
- We can feed new observations into the model and get probabilities for the outcome