5 SLURM Scheduler
- Describe the role of a job scheduler on a HPC cluster.
- Submit a simple job using SLURM and recognise where the output is saved to.
- Edit job submission scripts to request non-default resources.
- Use SLURM environment variables to customise scripts.
- Monitor the progress of a job using commands such as
squeueandseff. - Troubleshoot errors during and after job execution.
5.1 Job Scheduler Overview
As we briefly discussed in “Introduction to HPC”, HPC servers usually have a job scheduler software that manages all the jobs that the users submit to be run on the compute nodes. This allows efficient usage of the compute resources (CPUs and RAM), and the user does not have to worry about affecting other people’s jobs.
The job scheduler uses an algorithm to prioritise the jobs, weighing aspects such as:
- How much time did you request to run your job?
- How many resources (CPUs and RAM) do you need?
- How many other jobs have you got running at the moment?
Based on these, the algorithm will rank each of the jobs in the queue to decide on a “fair” way to prioritise them. Note that this priority dynamically changes all the time, as jobs are submitted or cancelled by the users, and depending on how long they have been in the queue. For example, a job requesting many resources may start with a low priority, but the longer it waits in the queue, the more its priority increases.
In these materials we will cover a job scheduler called SLURM, however the way this scheduler works is very similar to other schedulers. The specific commands may differ, but the functionality is the same (see this document for matching commands to other job sheculers).
5.2 Submitting a Job with SLURM
To submit a job to SLURM, you need to include your code in a shell script. Let’s start with a minimal example, found in our workshop data folder “slurm”.
Our script is called simple_job.sh and contains the following code:
#!/bin/bash
sleep 60 # hold for 60 seconds
echo "This job is running on:"
hostnameWe can run this script from the login node using the bash interpreter (make sure you are in the correct directory first: cd ~/rds/hpc-work/hpc_workshop/):
bash job_scripts/simple_job.shWhich prints the output:
This job is running on:
login-nodeTo submit the job to the scheduler we instead use the sbatch command in a very similar way:
sbatch job_scripts/simple_job.shIn this case, we are informed that the job is submitted to the SLURM queue. We can see all our jobs in the queue with:
squeue --meJOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
193 training simple_j particip R 0:02 1 training-dy-t2medium-2This gives a list of all the jobs running, with their “status” (ST column), which is usually:
PDfor a pending job, meaning the job is waiting the queue to get started.Rfor a running job, meaning the job is currently running on one of the compute nodes.
But if our job is running on a compute node, where does the output go? Instead of being printed to the terminal, the output of this script will be saved to a file. By default the file is named slurm-JOBID.out, where “JOBID” is a number corresponding to the job ID assigned to the job by the scheduler. This file will be located in the same directory where you launched the job from.
We can investigate the output by looking inside the file, for example cat slurm-JOBID.out.
The first line of the shell scripts #!/bin/bash is called a shebang and indicates which program should interpret this script. In this case, bash is the interpreter of shell scripts (there’s other shell interpreters, but that’s beyond what we need to worry about here).
Remember to always have this as the first line of your script. If you don’t, sbatch will throw an error.
5.3 Configuring Job Options
Although the above example works, our job just ran with the default options that SLURM was configured with. Instead, we usually want to customise our job, by specifying options at the top of the script using the #SBATCH keyword, followed by the SLURM option.
For example, one option we may want to change in our previous script is the name of the file to where our standard output is written to. We can do this using the -o option.
Here is how we could modify our script (you can do it using Nano or VS Code):
#!/bin/bash
#SBATCH -o job_logs/simple_job.log
sleep 8 # hold for 8 seconds
echo "This job is running on:"
hostnameIf we now re-run the script using sbatch simple_job.sh, the output goes to a file named simple_job.log.
There are several other options we can specify when using SLURM, and we will encounter several more of them as we progress through the materials. Here are some of the most common ones (anything in <> is user input):
| Command | Description |
|---|---|
-D <path> |
working directory used for the job. This is the directory that SLURM will use as a reference when running the job. |
-o <path/filename> |
file where the output that would normally be printed on the console is saved in. This is defined relative to the working directory set above. |
-A <name> |
billing account. This is sometimes needed if you’re using HPC servers that charge you for their use. This information should be provided by your HPC admins. |
-p <name> |
partition name. See details in the following section. |
-c <number> |
the number of CPUs you want to use for your job. |
-t <HH:MM:SS> |
the time you need for your job to run. This is not always easy to estimate in advance, so if you’re unsure you may want to request a good chunk of time. However, the more time you request for your job, the lower its priority in the queue. |
--mem=<number>GB |
how much RAM memory you want for your job in gigabytes. |
-J <name> |
a name for the job. |
If you don’t specify any options when submitting your jobs, you will get the default configured by the HPC admins. For example, in our Cambridge HPC, the defaults you will get are:
- 10 minutes of running time (equivalent to
-t 00:10:00) - cclake partition (equivalent to
-p cclake) - 1 CPU (equivalent to
-c 1) - ~3.4 GiB RAM (equivalent to
--mem=3.4G)
5.3.1 Partitions
Often, HPC servers have different types of compute node setups (e.g. queues for fast jobs, or long jobs, or high-memory jobs, etc.). SLURM calls these “partitions” and you can use the -p option to choose which partition your job runs on. Usually, which partitions are available on your HPC should be provided by the admins.
It’s worth keeping in mind that partitions have separate queues, and you should always try to choose the partition that is most suited to your job.
For example, on the Cambridge HPC we have several partitions, here are two examples:
cclakepartition (default)- Maximum 56 CPUs (default: 1)
- Maximum 3928 MB RAM (default: 1024)
traininglargepartition- Maximum 8 CPUs (default: 1)
- Maximum 31758 MB RAM (default: 1024)
5.4 Getting Job Information
After submitting a job, we may want to know:
- What is going on with my job? Is it running or has it finished?
- If it finished, did it finish successfully, or did it fail?
- How many resources (e.g. RAM) did it use?
- What if I want to cancel a job because I realised there was a mistake in my script?
We’ve already seen the squeue command to check the status of your jobs. Without any options you will get all jobs in the queue (yours and other users’). To see only your jobs you can add the --me option, or -u <your-username>:
squeue --me # list the jobs for my user
squeue -u <username> # list the jobs for a specific userThis gives you information about the job’s status: PD means it’s pending (waiting in the queue) and R means it’s running on a compute node.
To see more information for a job (and whether it completed or failed), you can use:
seff JOBIDThis shows you the status of the job (running, completed, failed), how many cores it used, how long it took to run and how much memory it used. Therefore, this command is very useful to determine suitable resources (e.g. RAM, time) next time you run a similar job.
Alternatively, you can use the sacct command, which allows displaying this and other information in a more condensed way (and for multiple jobs if you want to).
For example:
sacct --format JobName,Account,State,AllocCPUs,ReqMem,MaxRSS,AveRSS,Elapsed -j JOBIDJobNameis the job’s nameAccountis the account used for the jobStategives you the state of the jobAllocCPUsis the number of CPUs you requested for the jobReqMemis the memory that you asked for (Mc or Gc indicates MB or GB per core; Mn or Gn indicates MB or GB per node)MaxRSSis the maximum memory used during the job per coreAveRSSis the average memory used per coreElapsedhow much time it took to run your job
All the format options available with sacct can be listed using sacct -e.
If you forgot what your job id is, running sacct with no other options will show you information about the jobs that ran recently. If you want to know the ID of jobs that ran in a period of time, you can do:
sacct -S 2024-01-01 -E 2024-02-01 --format=JobID,JobName,Start,End,StateHere, -S is the start date and -E the end date of the time period you want to list jobs for. You can omit the -E option, in which case it will list all the jobs that ran up to the current date.
The sacct command may not be available on every HPC, as it depends on how it was configured by the admins.
You can also see more details about a job, such as the working directory and output directories, using:
scontrol show job <JOBID>Finally, if you want to cancel a job, you can use:
scancel <JOBID>And to cancel all your jobs simultaneously: scancel -u <USERNAME> (you will not be able to cancel other people’s jobs, so don’t worry about it).
5.4.1 Exercise: Submit SLURM job
Before starting this exercise make sure you are in the workshop folder (cd ~/rds/hpc-work/hpc_workshop).
In the “analysis_scripts” directory, you will find a Python script called pi_estimator.py. This script tries to get an approximate estimate for the number Pi using a stochastic algorithm.
How does the algorithm work?
If you are interested in the details, here is a short description of what the script does:
The program generates a large number of random points on a 1×1 square centered on (½,½), and checks how many of these points fall inside the unit circle. On average, π/4 of the randomly-selected points should fall in the circle, so π can be estimated from 4f, where f is the observed fraction of points that fall in the circle. Because each sample is independent, this algorithm is easily implemented in parallel.
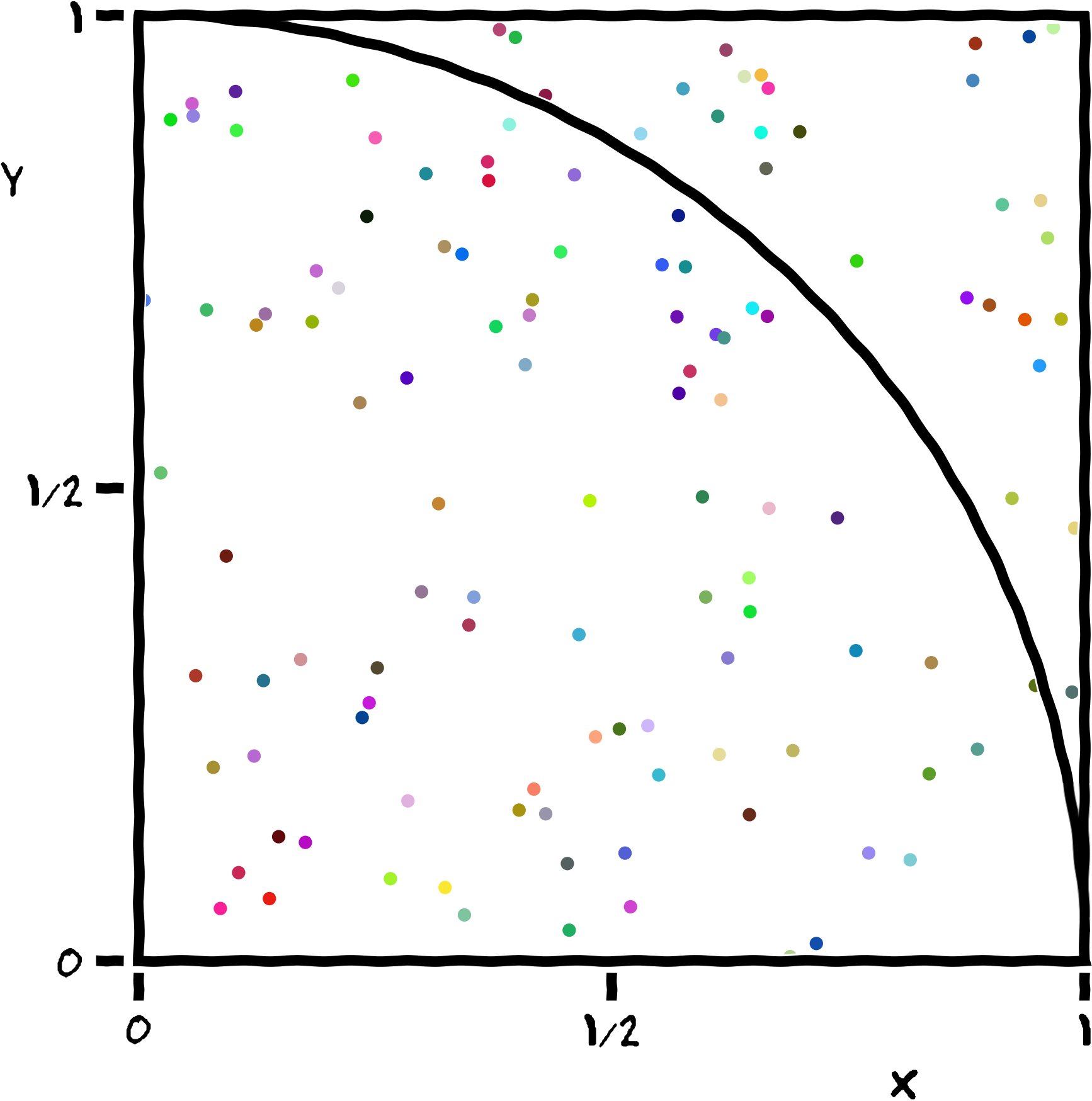
If you were running this script interactively (i.e. directly from the console), you would use the Python interpreter: python3 analysis_scripts/pi_estimator.py. Instead, we use a shell script to submit this to the job scheduler.
- Edit the shell script in
job_scripts/estimate_pi.shby correcting your username in the working directory path (under#SBATCH -D). Submit the job to SLURM and check its status in the queue. - Did your job run successfully, and how long did it take to run?
- The number of samples used to estimate Pi can be modified using the
--nsamplesoption of our script, defined in millions. The more samples we use, the more precise our estimate should be.- Adjust your SLURM submission script to use 50 million samples (
python3 analysis_scripts/pi_estimator.py --nsamples 50), and save the job output injob_logs/estimate_pi_50M.log. - Monitor the job status with
squeueandseff JOBID. Do you find any issues? How would you fix it?
- Adjust your SLURM submission script to use 50 million samples (
5.5 SLURM Environment Variables
One useful feature of SLURM jobs is the automatic creation of environment variables. Generally speaking, variables are a character that store a value within them, and can either be created by us, or sometimes they are automatically created by programs or available by default in our shell.
An example of a common shell environment variable is $HOME, which stores the path to the user’s /home directory. We can print the value of a variable with echo $HOME.
The syntax to create a variable ourselves is:
VARIABLE="value"Notice that there should be no space between the variable name and its value.
If you want to create a variable with the result of evaluating a command, then the syntax is:
VARIABLE=$(command)Try these examples:
# Make a variable with a path starting from the user's /home
DATADIR="$HOME/rds/hpc-work/data/"
# list files in that directory
ls $DATADIR
# create a variable with the output of that command
DATAFILES=$(ls $DATADIR)When you submit a job with SLURM, it creates several variables, all starting with the prefix $SLURM_. One useful variable is $SLURM_CPUS_PER_TASK, which stores how many CPUs we requested for our job. This means that we can use the variable to automatically set the number of CPUs for software that support multi-processing. We will see an example in the following exercise.
Here is a table summarising some of the most useful environment variables that SLURM creates:
| Variable | Description |
|---|---|
$SLURM_CPUS_PER_TASK |
Number of CPUs requested with -c |
$SLURM_JOB_ID |
The job ID |
$SLURM_JOB_NAME |
The name of the job defined with -J |
$SLURM_SUBMIT_DIR |
The working directory defied with -D |
$SLURM_ARRAY_TASK_ID |
The number of the sub-job when running parallel arrays (covered in the Job Arrays section) |
5.5.1 Exercise: SLURM environment variables
5.6 Interactive Login
Sometimes it may be useful to directly get a terminal on one of the compute nodes. This may be useful, for example, if you want to test some scripts or run some code that you think might be too demanding for the login node (e.g. to compress some files).
It is possible to get interactive access to a terminal on one of the compute nodes using the sintr command. This command takes options similar to the sbatch program, so you can request resources in the same way you would when submitting scripts.
For example, to access to 8 CPUs and 10GB of RAM for 1h on one of the compute nodes we would do:
sintr -c 8 --mem=10G -p icelake -t 01:00:00 -A TRAINING-CPUYou may get a message saying that SLURM is waiting to allocate your request (you go in the queue, just like any other job!). Eventually, when you get in, you will notice that your terminal will indicate you are on a different node (different from the login node). You can check by running hostname.
After you’re in, you can run any commands you wish, without worrying about affecting other users’ work. Once you are finished, you can use the command exit to terminate the session, and you will go back to the login node.
Note that, if the time you requested (with the -t option) runs out, your session will be immediately killed.
The main purpose of interactive jobs is to quickly test code or to run routine tasks such as compressing/uncompressing large files. You should not use interactive jobs for your actual analysis.
The main reason is that interactive jobs require users to actively monitor and manage their tasks, which may not be the most efficient use of their time. This may also result in congesting the job queue, causing delays for other users with batch jobs waiting to be processed. Furthermore, batch jobs can be scheduled to run during off-peak hours, allowing users to focus on other tasks while their computations are being processed.
For this reason, some HPC clusters are configured to limit the time for interactive jobs (for example, at Cambridge University these are limited to 1h).
5.7 Summary
- Include the commands you want to run on the HPC in a shell script.
- Always remember to include
#!/bin/bashas the first line of your script.
- Always remember to include
- Submit jobs to the scheduler using
sbatch submission_script.sh. - Customise the jobs by including
#SBATCHoptions at the top of your script (see table in the materials above for a summary of options).- As a good practice, always define an output file with
#SBATCH -o. All the information about the job will be saved in that file, including any errors.
- As a good practice, always define an output file with
- Check the status of a submitted job by using
squeue --meandseff JOBID. - To cancel a running job use
scancel JOBID.
See this SLURM cheatsheet for a summary of the available commands.