3 HPC Introduction
These materials have accompanying slides: Introduction to HPC slides
- Describe how a typical HPC is organised: nodes, job scheduler and filesystem.
- Distinguish the roles of a login node and a compute node.
- Describe the role of a job scheduler.
- Understand the difference between “scratch” and “home” storage.
- Understand how files and folders are organised on the Sanger farm servers.
3.1 What is a HPC and what are its uses?
HPC stands for high-performance computing and usually refers to several computers connected together in a network (forming a HPC cluster). Each of these computers is referred to as a node in the network.
The main usage of HPC clusters is to run resource-intensive and/or parallel tasks. For example: running thousands of simulations, each one taking several hours; assembling a genome from sequencing data, which requires computations on large volumes of data in memory. These tasks would be extremely challenging to complete on a regular computer. However, they are just the kind of task that a HPC would excel at.
The terms HPC, cluster, and farm are often used interchangeably to mean the same thing.
When working on a HPC it is important to understand what kinds of resources are available to us. These are the main resources we need to consider:
- CPU (central processing units) is the “brain” of the computer, performing a wide range of operations and calculations. CPUs can have several “cores”, which means they can run tasks in parallel, increasing the throughput of calculations per second. A typical personal computer may have a CPU with 4-8 cores. A single compute node on the HPC may have 32-48 cores (and often these are faster than the CPU on our computers).
- RAM (random access memory) is a quick access storage where data is temporarily held while being processed by the CPU. A typical personal computer may have 8-32Gb of RAM. A single compute nodes on a HPC may often have >100Gb RAM.
- GPUs (graphical processing units) are similar to CPUs, but are more specialised in the type of operations they can do. While less flexible than CPUs, each GPU can do thousands of calculations in parallel. This makes them extremely well suited for graphical tasks, but also more generally for matrix computations and so are often used in machine learning applications.
Usually, HPC servers are available to members of large institutions (such as a Universities or research institutes) or sometimes from cloud providers. This means that:
- There are many users, who may simultaneously be using the HPC.
- Each user may want to run several jobs concurrently.
- Often large volumes of data are being processed and there is a need for high-performance storage (allowing fast read-writting of files).
So, at any one time, across all the users, there might be many thousands of processes running on the HPC! There has to be a way to manage all this workload, and this is why HPC clusters are typically organised somewhat differently from what we might be used to when we work on our own computers. Figure 1 shows a schematic of a HPC, and we go into its details in the following sections.

3.1.1 Nodes
There are two types of nodes on a cluster (Figure 1):
- login nodes (also known as head or submit nodes).
- compute nodes (also known as worker nodes).
The login nodes are the computers that the user connects to and from where they interact with the cluster. Depending on the size of the cluster, there is often only one login node, but larger clusters may have several of them. Login nodes are used to interact with the filesystem (move around the directories), download and move files, edit and/or view text files and doing other small routine tasks.
The compute nodes are the machines that will actually do the hard work of running jobs. These are often high-spec computers with many CPUs and high RAM (or powerful GPU cards), suitable for computationally demanding tasks. Often, there are several “flavours” of compute nodes on the same cluster. For example some compute nodes may have fewer CPUs but higher memory (suitable for memory-intensive tasks), while others may have the opposite (suitable for highly-parallelisable tasks).
Users do not have direct access to the compute nodes and instead submitting jobs via a job scheduler.
3.1.2 Job Scheduler
A job scheduler is a software used to submit commands to be run on the compute nodes (orange box in Figure 1). This is needed because there may often be thousands of processes that all the users of the HPC want to run at any one time. The job scheduler’s role is to manage all these jobs, so you don’t have to worry about it.
We will cover the details of how to use a job scheduler in “Using the LSF Job Scheduler”. For now, it is enough to know that, using the job scheduler, the user can request specific resources to run their job (e.g. number of cores, RAM, how much time we want to reserve the compute node to run our job, etc.). The job scheduler software then takes care of considering all the jobs being submitted by all the users and putting them in a queue until there are compute nodes available to run the job with the requested resources.

In terms of parallelising calculations, there are two ways to think about it, and which one we use depends on the specific application. Some software packages have been developed to internally parallelise their calculations (or you may write your own script that uses a parallel library). These are very commonly used in bioinformatic applications, for example. In this case we may want to submit a single job, requesting several CPU cores for it.
In other cases, we may have a program that does not parallelise its calculations, but we want to run many iterations of it. A typical example is when we want to run simulations: each simulation only uses a single core, but we want to run thousands of them. In this case we would want to submit each simulation as a separate job, but only request a single CPU core for each job.
Finally, we may have a case where both of these are true. For example, we want to process several data files, where each data file can be processed using tools that parallelise their calculations. In this case we would want to submit several jobs, requesting several CPU cores for each.
3.1.3 Filesystem
The filesystem on a HPC cluster often consists of storage partitions that are shared across all the nodes, including both the login and compute nodes (green box in Figure 1). This means that data can be accessed from all the computers that compose the HPC cluster.
Although the filesystem organisation may differ depending on the institution, typical HPC servers often have two types of storage:
- The user’s home directory (e.g.
/home/user) is the default directory that one lands on when logging in to the HPC. This is often quite small and possibly backed up. The home directory can be used for storing things like configuration files or locally installed software. - A scratch space (e.g.
/scratch/user), which is high-performance, large-scale storage. This type of storage may be private to the user or shared with a group. It is usually not backed up, so the user needs to ensure that important data are stored elsewhere. This is the main partition were data is processed from.
Sanger Filesystem
At the Sanger Institute, the HPC is called the “farm” and is organised into 3 storage partitions:
- An NFS directory with long-term, backed-up storage for data, located at
/nfs. In addition to housing your home directory (at/nfs/users/nfs_[first_initial_of_username]/[sanger_username]), this contains iRODS directories where sequencing data from pipelines are kept, programme-specific file storage systems likecancer_reffor CASM, and team-specific storage. NFS files are intended to be ‘read only’ as computation should not be done directly from this folder; you’re advised to move files over to scratch for heavy input/output work. This moving step is called “staging” at the Sanger, and there is an internal module to help with this process. - A system of scratch directories stored in a system called lustre housed in
/lustre. Lustre has a lot of storage but is not backed up. There are a series of scratch folders within lustre, each with nested subfolders for Sanger programmes (e.g. casm), groups (e.g. team154pc), and users (e.g. cp19). Permissions to each folder are managed by the Service Desk — to join your group’s scratch folder you must first identify which directories you need access to (ask a labmate) and email the Service Desk (service@sanger.ac.uk). For example,/lustre/scratchxxx/team154pc/cp19. - Warehouse is another long-term storage system predominantly used by the Service Desk to arrange group permissions. You most likely won’t need this at all in your day-to-day work (which should mainly be in lustre).
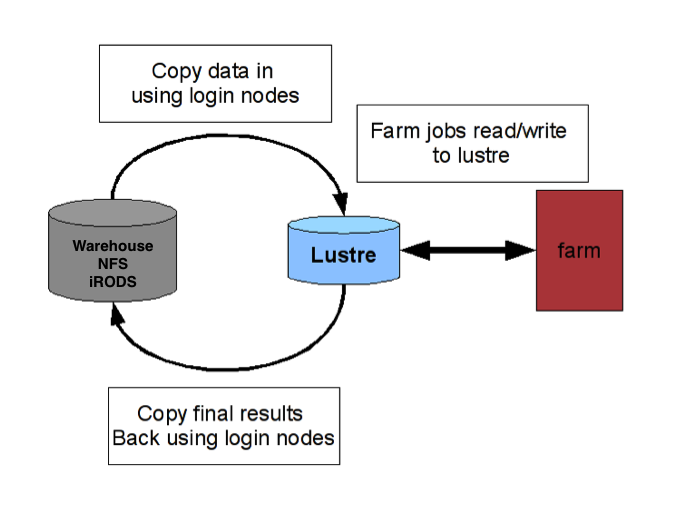
Example workflow for Sanger data analysis
The Sanger has pipelined both wet lab sequencing steps and initial data analysis (i.e. aligning and variant calling). You have to request these using programme-specific workflows, but the actual computational steps are done by the pipelines teams. The resultant raw data and initial data analysis outfiles are stored within NFS, which you can access for further analysis and visualisation.
- Submit a request for sequencing.
- Through this process, your submission will be assigned a project ID number and a sample ID (PD*****).
- Request additional analysis. (optional)
- In addition to standard alignment, some programmes (CASM, CellGen, etc.) offer in-house analysis like variant calling for DNA or HTSeq for RNA. This is requested by either emailing your programme’s service desk or through programme-specific webpages (i.e. Canapps).
- Locate raw data or processed data.
- All Sanger data are stored on iRODS, an efficient storage system separate from the Farm. Instructions for accessing these raw or aligned data are here.
- Some programmes may symlink iRODS data to designated NFS directories for easy access of both BAM files and pipelined analysis (variant calling, structural variant calling, etc.).
- Transfer data from NFS to Lustre.
- We can only read files within NFS (iRODS or programme-specific directory), so for downstream analysis the files must be moved to your Lustre scratch folder. This moving process is called staging and there is a Sanger module that makes this process easy and efficient.
- Analyse data.
- Submit a job to the LSF scheduler using bsub.
- Transfer results from Farm to local computer.
- Use a FTP tool to move desired results to your local machine.
3.2 Getting Help
In most cases there will be a HPC administrator (or team), who you can reach out for help if you need to obtain more information about how your HPC is organised. At the Sanger, you can contact the Service Desk at service@sanger.ac.uk with farm-related queries.
Some of the questions you may want to ask when you start using a new HPC are:
- what kind of compute nodes are available?
- what storage do I have access to, and how much?
- what job scheduler software is used, and can you give me an example submission script to get started?
- will I be charged for the use of the HPC?
Also, it is often the case that the HPC needs some maintenance service, and you should be informed that this is happening (e.g. by a mailing list). At the Sanger, this mailing list is farm-users@sanger.ac.uk, to which you’ll be automatically added once you complete the Farm Induction course and gain access to the farm.
Sometimes things stop working or break, and there may be some time when your HPC is not available while work is being done on it. You’ll be kept in the loop on these outages via the farm users mailing list.
3.3 Exercises
3.4 Summary
- A HPC consists of several computers connected in a network. These are called nodes:
- The login nodes are the machines that we connect to and from where we interact with the HPC. These should not be used to run resource-intensive tasks.
- The compute nodes are the high-performance machines on which the actual heavy computations run. Jobs are submitted to the compute nodes through a job scheduler.
- The job scheduler is used to submit scripts to be run on the compute nodes.
- The role of this software is to manage large numbers of jobs being submitted and prioritise them according to their resource needs.
- We can configure how our jobs are run by requesting the adequate resources (CPUs and RAM memory).
- Choosing resources appropriately helps to get our jobs the right level of priority in the queue.
- The filesystem on a HPC is often split between a small (backed) home directory, and a large and high-performance (non-backed) scratch space.
- The user’s home is used for things like configuration files and local software instalation.
- The scratch space is used for the data and analysis scripts.
- Not all HPC servers have this filesystem organisation - always check with your local HPC admin.
- At the Sanger there are two types of storage:
- NFS: used for the user’s home directories and for iRODs (which contains sequencing data from the Sanger pipelines).
- Lustre: used for high-performance compute operations, and the designated storage that should be used for running analysis on the HPC.